Complexity: A Guided Tour - Melanie Mitchell (2009)
Part I. Background and History
Chapter 6. Genetics, Simplified
SOME OF THE CHALLENGES to the Modern Synthesis have found support in the last several decades in results coming from molecular biology, which have changed most biologists’ views of how evolution takes place.
In chapter 18, I describe some of these results and their impact on genetics and evolutionary theory. As background for this and other discussions throughout the book, I give here a brief review of the basics of genetics. If you are already familiar with this subject, this chapter can be skipped.
It has been known since the early 1800s that all living organisms are composed of tiny cells. In the later 1800s, it was discovered that the nucleus of every cell contains large, elongated molecules that were dubbed chromosomes(“colored bodies,” since they could be stained so easily in experiments), but their function was not known. It also was discovered that an individual cell reproduces itself by dividing into two identical cells, during which process (dubbed mitosis) the chromosomes make identical copies of themselves. Many cells in our bodies undergo mitosis every few hours or so—it is an integral process of growth, repair, and general maintenance of the body.
Meiosis, discovered about the same time, is the process in diploid organisms by which eggs and sperm are created. Diploid organisms, including most mammals and many other classes of organisms, are those in which chromosomes in all cells (except sperm and egg, or germ cells) are found in pairs (twenty-three pairs in humans). During meiosis, one diploid cell becomes four germ cells, each of which has half the number of chromosomes as the original cell. Each chromosome pair in the original cell is cut into parts, which recombine to form chromosomes for the four new germ cells. During fertilization, the chromosomes in two germ cells fuse together to create the correct number of chromosome pairs.
The result is that the genes on a child’s chromosome are a mixed-up version of its parents’ chromosomes. This is a major source of variation in organisms with sexual reproduction. In organisms with no sexual reproduction the child looks pretty identical to the parent.
All this is quite complicated, so it is no surprise that biologists took a long time to unravel how it all works. But this was just the beginning.
The first suggestion that chromosomes are the carriers of heredity was made by Walter Sutton in 1902, two years after Mendel’s work came to be widely known. Sutton hypothesized that chromosomes are composed of units (“genes”) that correspond to Mendelian factors, and showed that meiosis gives a mechanism for Mendelian inheritance. Sutton’s hypothesis was verified a few years later by Thomas Hunt Morgan via experiments on that hero of genetics, the fruit fly. However, the molecular makeup of genes, or how they produced physical traits in organisms, was still not known.
By the late 1920s, chemists had discovered both ribonucleic acid (RNA) and deoxyribonucleic acid (DNA), but the connection with genes was not discovered for several more years. It became known that chromosomes contained DNA, and some people suspected that this DNA might be the substrate of genes. Others thought that the substrate consisted of proteins found in the cell nucleus. DNA of course turned out to be the right answer, and this was finally determined experimentally by the mid-1940s.
But several big questions remained. How exactly does an organism’s DNA cause the organism to have particular traits, such as tall or dwarf stems? How does DNA create a near-exact copy of itself during cell division (mitosis)? And how does the variation, on which natural selection works, come about at the DNA level?
These questions were all answered, at least in part, within the next ten years. The biggest break came when, in 1953, James Watson and Francis Crick figured out that the structure of DNA is a double helix. In the early 1960s, the combined work of several scientists succeeded in breaking the genetic code—how the parts of DNA encode the amino acids that make up proteins. A gene—a concept that had been around since Mendel without any understanding of its molecular substrate—could now be defined as a substring of DNA that codes for a particular protein. Soon after this, it was worked out how the code was translated by the cell into proteins, how DNA makes copies of itself, and how variation arises via copying errors, externally caused mutations, and sexual recombination. This was clearly a “tipping point” in genetics research. The science of genetics was on a roll, and hasn’t stopped rolling yet.
The Mechanics of DNA
The collection of all of an organism’s physical traits—its phenotype—comes about largely due to the character of and interactions between proteins in cells. Proteins are long chains of molecules called amino acids.
Every cell in your body contains almost exactly the same complete DNA sequence, which is made up of a string of chemicals called nucleotides. Nucleotides contain chemicals called bases, which come in four varieties, called (for short) A, C, G, and T. In humans, strings of DNA are actually double strands of paired A, C, G, and T molecules. Due to chemical affinities, A always pairs with T, and C always pairs with G.
Sequences are usually written with one line of letters on the top, and the paired letters (base pairs) on the bottom, for example,
TCCGATT …
AGGCTAA …
In a DNA molecule, these double strands weave around one another in a double helix (figure 6.1).
Subsequences of DNA form genes. Roughly, each gene codes for a particular protein. It does that by coding for each of the amino acids that make up the protein. The way amino acids are coded is called the genetic code. The code is the same for almost every organism on Earth. Each amino acid corresponds to a triple of nucleotide bases. For example, the DNA triplet AAG corresponds to the amino acid phenylalanine, and the DNA triplet C A C corresponds to the amino acid valine. These triplets are called codons.
So how do proteins actually get formed by genes? Each cell has a complex set of molecular machinery that performs this task. The first step is transcription (figure 6.2), which happens in the cell nucleus. From a single strand of the DNA, an enzyme (an active protein) called RNA polymerase unwinds a small part of the DNA from its double helix. This enzyme then uses one of the DNA strands to create a messenger RNA (or mRNA) molecule that is a letter-for-letter copy of the section of DNA. Actually, it is an anticopy: in every place where the gene has C, the mRNA has G, and in every place where the gene has A, the mRNA has U (its version of T). The original can be reconstructed from the anticopy.
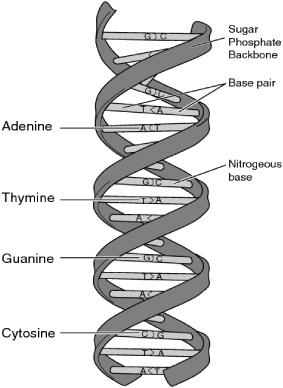
FIGURE 6.1. Illustration of the double helix structure of DNA. (From the National Human Genome Research Institute, Talking Glossary of Genetic Terms [http://www.genome.gov/glossary.cfm.])
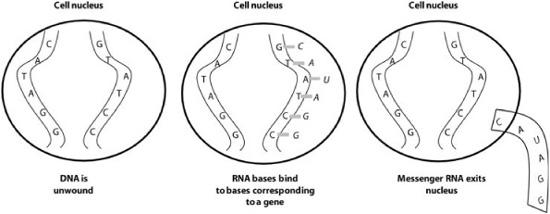
FIGURE 6.2. Illustration of transcription of DNA into messenger RNA. Note that the letter U is RNA’s version of DNA’s letter T.
The process of transcription continues until the gene is completely transcribed as mRNA.
The second step is translation (figure 6.3), which happens in the cell cytoplasm. The newly created mRNA strand moves from the nucleus to the cytoplasm, where it is read, one codon at a time, by a cytoplasmic structure called a ribosome. In the ribosome, each codon is brought together with a corresponding anticodon residing on a molecule of transfer RNA (tRNA). The anticodon consists of the complementary bases. For example, in figure 6.3, the mRNA codon being translated is UAG, and the anticodon is the complementary bases AUC.A tRNA molecule that has that anticodon will attach to the mRNA codon, as shown in the figure. It just so happens that every tRNA molecule has attached to it both an anticodon and the corresponding amino acid (the codon A U C happens to code for the amino acid isoleucine in case you were interested). Douglas Hofstadter has called tRNA “the cell’s flash cards.”
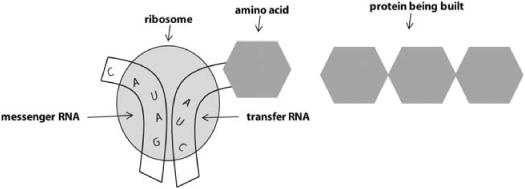
FIGURE 6.3. Illustration of translation of messenger RNA into amino acids.
The ribosome cuts off the amino acids from the tRNA molecules and hooks them up into a protein. When a stop-codon is read, the ribosome gets the signal to stop, and releases the protein into the cytoplasm, where it will go off and perform whatever function it is supposed to do.
The transcription and translation of a gene is called the gene’s expression and a gene is being expressed at a given time if it is being transcribed and translated.
All this happens continually and simultaneously in thousands of sites in each cell, and in all of the trillions of cells in your body. It’s amazing how little energy this takes—if you sit around watching TV, say, all this subcellular activity will burn up fewer than 100 calories per hour. That’s because these processes are in part fueled by the random motion and collisions of huge numbers of molecules, which get their energy from the “ambient heat bath” (e.g., your warm living room).
The paired nature of nucleotide bases, A with T and C with G, is also the key to the replication of DNA. Before mitosis, enzymes unwind and separate strands of DNA. For each strand, other enzymes read the nucleotides in the DNA strand, and to each one attach a new nucleotide (new nucleotides are continually manufactured in chemical processes going on in the cell), with A attached to T, and C attached to G, as usual. In this way, each strand of the original two-stranded piece of DNA becomes a new two-stranded piece of DNA, and each cell that is the product of mitosis gets one of these complete two-stranded DNA molecules. There are many complicated processes in the cell that keep this replication process on track. Occasionally (about once every 100 billion nucleotides), errors will occur (e.g., a wrong base will be attached), resulting in mutations.
It is important to note that there is a wonderful self-reference here: All this complex cellular machinery—the mRNA, tRNA, ribosomes, polymerases, and so forth—that effect the transcription, translation, and replication of DNA are themselves encoded in that very DNA. As Hofstadter remarks: “The DNA contains coded versions of its own decoders!” It also contains coded versions of all the proteins that go into synthesizing the nucleotides the DNA is made up of. It’s a self-referential circularity that would no doubt have pleased Turing, had he lived to see it explained.
The processes sketched above were understood in their basic form by the mid-1960s in a heroic effort by geneticists to make sense of this incredibly complex system. The effort also brought about a new understanding of evolution at the molecular level.
In 1962, Crick, Watson, and biologist Maurice Wilkins jointly received the Nobel prize in medicine for their discoveries about the structure of DNA. In 1968, Har Gobind Korana, Robert Holley, and Marshall Nirenberg received the same prize for their work on cracking the genetic code. By this time, it finally seemed that the major mysteries of evolution and inheritance had been mostly worked out. However, as we see in chapter 18, it is turning out to be a lot more complicated than anyone ever thought.