Complexity: A Guided Tour - Melanie Mitchell (2009)
Part I. Background and History
Chapter 3. Information
The law that entropy increases—the Second Law of Thermodynamics—holds, I think, the supreme position among the laws of Nature… [I] f your theory is found to be against the Second Law of Thermodynamics I can give you no hope; there is nothing for it but to collapse in deepest humiliation.
—Sir Arthur Eddington, The Nature of the Physical World
COMPLEX SYSTEMS ARE OFTEN said to be “self-organizing”: consider, for example, the strong, structured bridges made by army ants; the synchronous flashing of fireflies; the mutually sustaining markets of an economy; and the development of specialized organs by stem cells—all are examples of self-organization. Order is created out of disorder, upending the usual turn of events in which order decays and disorder (or entropy) wins out.
A complete account of how such entropy-defying self-organization takes place is the holy grail of complex systems science. But before this can be tackled, we need to understand what is meant by “order” and “disorder” and how people have thought about measuring such abstract qualities.
Many complex systems scientists use the concept of information to characterize and measure order and disorder, complexity and simplicity. The immunologist Irun Cohen states that “complex systems sense, store, and deploy more information than do simple systems.” The economist Eric Beinhocker writes that “evolution can perform its tricks not just in the ‘substrate’ of DNA but in any system that has the right information processing and information storage characteristics.” The physicist Murray Gell-Mann said of complex adaptive systems that “Although they differ widely in their physical attributes, they resemble one another in the way they handle information. That common feature is perhaps the best starting point for exploring how they operate.”
But just what is meant by “information”?
What Is Information?
You see the word “information” all over the place these days: the “information revolution,” the “information age,” “information technology” (often simply “IT”), the “information superhighway,” and so forth. “Information” is used colloquially to refer to any medium that presents knowledge or facts: newspapers, books, my mother on the phone gossiping about relatives, and, most prominently these days, the Internet. More technically, it is used to describe a vast array of phenomena ranging from the fiber-optic transmissions that constitute signals from one computer to another on the Internet to the tiny molecules that neurons use to communicate with one another in the brain.
The different examples of complex systems I described in chapter 1 are all centrally concerned with the communication and processing of information in various forms. Since the beginning of the computer age, computer scientists have thought of information transmission and computation as something that takes place not only in electronic circuits but also in living systems.
In order to understand the information and computation in these systems, the first step, of course, is to have a precise definition of what is meant by the terms information and computation. These terms have been mathematically defined only in the twentieth century. Unexpectedly, it all began with a late nineteenth-century puzzle in physics involving a very smart “demon” who seemed to get a lot done without expending any energy. This little puzzle got many physicists quite worried that one of their fundamental laws might be wrong. How did the concept of information save the day? Before getting there, we need a little bit of background on the physics notions of energy, work, and entropy.
Energy, Work, and Entropy
The scientific study of information really begins with the science of thermodynamics, which describes energy and its interactions with matter. Physicists of the nineteenth century considered the universe to consist of two different types of entities: matter (e.g., solids, liquids, and vapors) and energy (e.g., heat, light, and sound).
Energy is roughly defined as a system’s potential to “do work,” which correlates well with our intuitive notion of energy, especially in this age of high-energy workaholics. The origin of the term is the Greek word, energia, which literally means “to work.” However, physicists have a specific meaning of “work” done by an object: the amount of force applied to the object multiplied by the distance traveled by the object in the direction that force was applied.
For example, suppose your car breaks down on a flat road and you have to push it for a quarter of a mile to the nearest gas station. In physics terms, the amount of work that you expend is the amount of force with which you push the car multiplied by the distance to the gas station. In pushing the car, you transform energy stored in your body into the kinetic energy (i.e., movement) of the car, and the amount of energy that is transformed is equal to the amount of work that is done plus whatever energy is converted to heat, say, by the friction of the wheels on the road, or by your own body warming up. This so-called heat loss is measured by a quantity called entropy. Entropy is a measure of the energy that cannot be converted into additional work. The term “entropy” comes from another Greek word—“trope”—meaning “turning into” or “transformation.”
By the end of the nineteenth century two fundamental laws concerning energy had been discovered, the so-called laws of thermodynamics. These laws apply to “isolated systems”—ones that do not exchange energy with any outside entity.
First law: Energy is conserved. The total amount of energy in the universe is constant. Energy can be transformed from one form to another, such as the transformation of stored body energy to kinetic energy of a pushed car plus the heat generated by this action. However, energy can never be created or destroyed. Thus it is said to be “conserved.”
Second law: Entropy always increases until it reaches a maximum value. The total entropy of a system will always increase until it reaches its maximum possible value; it will never decrease on its own unless an outside agent works to decrease it.
As you’ve probably noticed, a room does not clean itself up, and Cheerios spilled on the floor, left to their own devices, will never find their way back into the cereal box. Someone or something has to do work to turn disorder into order.
Furthermore, transformations of energy, such as the car-pushing example above, will always produce some heat that cannot be put to work. This is why, for example, no one has found a way to take the heat generated by the back of your refrigerator and use it to produce new power for cooling the inside of the refrigerator so that it will be able to power itself. This explains why the proverbial “perpetual motion machine” is a myth.
The second law of thermodynamics is said to define the “arrow of time,” in that it proves there are processes that cannot be reversed in time (e.g., heat spontaneously returning to your refrigerator and converting to electrical energy to cool the inside). The “future” is defined as the direction of time in which entropy increases. Interestingly, the second law is the only fundamental law of physics that distinguishes between past and future. All other laws are reversible in time. For example, consider filming an interaction between elementary particles such as electrons, and then showing this movie to a physicist. Now run the movie backward, and ask the physicist which version was the “real” version. The physicist won’t be able to guess, since the forward and backward interactions both obey the laws of physics. This is what reversible means. In contrast, if you make an infrared film of heat being produced by your refrigerator, and show it forward and backward, any physicist will identify the forward direction as “correct” since it obeys the second law, whereas the backward version does not. This is what irreversible means. Why is the second law different from all other physical laws? This is a profound question. As the physicist Tony Rothman points out, “Why the second law should distinguish between past and future while all the other laws of nature do not is perhaps the greatest mystery in physics.”
Maxwell’s Demon
The British physicist James Clerk Maxwell is most famous for his discovery of what are now called Maxwell’s Equations: compact expressions of Maxwell’s theory that unified electricity and magnetism. During his lifetime, he was one of the world’s most highly regarded scientists, and today would be on any top fifty list of all-time greats of science.
In his 1871 book, Theory of Heat, Maxwell posed a puzzle under the heading “Limitation of the Second Law of Thermodynamics.” Maxwell proposed a box that is divided into two halves by a wall with a hinged door, as illustrated in figure 3.1. The door is controlled by a “demon,” a very small being who measures the velocity of air molecules as they whiz past him. He opens the door to let the fast ones go from the right side to the left side, and closes it when slow ones approach it from the right. Likewise, he opens the door for slow molecules moving from left to right and closes it when fast molecules approach it from the left. After some time, the box will be well organized, with all the fast molecules on the left and all the slow ones on the right. Thus entropy will have been decreased.

FIGURE 3.1. Top: James Clerk Maxwell, 1831-1879 (AIP Emilio Segre Visual Archives) Bottom: Maxwell’s Demon, who opens the door for fast (white) particles moving to the left and for slow (black) particles moving to the right.
According to the second law, work has to be done to decrease entropy. What work has been done by the demon? To be sure, he has opened and closed the door many times. However, Maxwell assumed that a massless and frictionless “slide” could be used as a door by the demon, so that opening and closing it would require negligible work, which we can ignore. (Feasible designs for such a door have been proposed.) Has any other work been done by the demon?
Maxwell’s answer was no: “the hot system [the left side] has gotten hotter and the cold [right side] colder and yet no work has been done, only the intelligence of a very observant and neat-fingered being has been employed.”
How did entropy decrease with little or no work being done? Doesn’t this directly violate the second law of thermodynamics? Maxwell’s demon puzzled many of the great minds of the late nineteenth and early twentieth centuries. Maxwell’s own answer to his puzzle was that the second law (the increase of entropy over time) is not really a law at all, but rather a statistical effect that holds for large collections of molecules, like the objects we encounter in day-to-day life, but does not necessarily hold at the scale of individual molecules.
However, many physicists of his day and long after vehemently disagreed. They believed that the second law has to remain inviolate; instead there must be something fishy about the demon. For entropy to decrease, work must actually have been done in some subtle, nonapparent way.
Many people tried to resolve the paradox, but no one was able to offer a satisfactory solution for nearly sixty years. In 1929, a breakthrough came: the great Hungarian physicist Leo Szilard (pronounced “ziLARD”) proposed that it is the “intelligence” of the demon, or more precisely, the act of obtaining information through measurement, that constitutes the missing work.
Szilard was the first to make a link between entropy and information, a link that later became the foundation of information theory and a key idea in complex systems. In a famous paper entitled “On the Decrease of Entropy in a Thermodynamic System by the Intervention of Intelligent Beings,” Szilard argued that the measurement process, in which the demon acquires a single “bit” of information (i.e., the information as to whether an approaching molecule is a slow one or a fast one) requires energy and must produce at least as much entropy as is decreased by the sorting of that molecule into the left or right side of the box. Thus the entire system, comprising the box, the molecules, and the demon, obeys the second law of thermodynamics.
In coming up with his solution, Szilard was perhaps the first to define the notion of a bit of information—the information obtained from the answer to a yes/no (or, in the demon’s case, “fast/slow”) question.

Leo Szilard, 1898-1964 (AIP Emilio Segre Visual Archives)
From our twenty-first-century vantage, it may seem obvious (or at least unsurprising) that the acquisition of information requires expenditure of work. But at the time of Maxwell, and even sixty years later when Szilard wrote his famous paper, there was still a strong tendency in people’s minds to view physical and mental processes as completely separate. This highly ingrained intuition may be why Maxwell, as astute as he was, did not see the “intelligence” or “observing powers” of the demon as relating to the thermodynamics of the box-molecules-demon system. Such relationships between information and physics became clear only in the twentieth century, beginning with the discovery that the “observer” plays a key role in quantum mechanics.
Szilard’s theory was later extended and generalized by the French physicists Leon Brillouin and Denis Gabor. Many scientists of the 1950s and later believed that Brillouin’s theory in particular had definitively finished off the demon by demonstrating in detail how making a measurement entails an increase of entropy.
However, it wasn’t over yet. Fifty years after Szilard’s paper, it was discovered that there were some holes in Szilard’s and Brillouin’s solutions as well. In the 1980s, the mathematician Charles Bennett showed that there are very clever ways to observe and remember information—in the demon’s case, whether an air molecule is fast or slow—without increasing entropy. Bennett’s remarkable demonstration of this formed the basis for reversible computing, which says that, in theory, any computation can be done without expending energy. Bennett’s discoveries might seem to imply that we are back at square one with the demon, since measurement can, in fact, be done without increasing entropy. However, Bennett noted that the second law of thermodynamics was saved again by an earlier discovery made in the 1960s by physicist Rolf Landauer: it is not the act of measurement, but rather the act of erasing memory that necessarily increases entropy. Erasing memory is not reversible; if there is true erasure, then once the information is gone, it cannot be restored without additional measurement. Bennett showed that for the demon to work, its memory must be erased at some point, and when it is, the physical act of this erasure will produce heat, thus increasing entropy by an amount exactly equal to the amount entropy was decreased by the demon’s sorting actions.
Landauer and Bennett’s solution to the paradox of Maxwell’s demon fixed holes in Szilard’s solution, but it was in the same spirit: the demon’s act of measurement and decision making, which requires erasure, will inevitably increase entropy, and the second law is saved. (I should say here that there are still some physicists who don’t buy the Landauer and Bennett solution; the demon remains controversial to this day.)
Maxwell invented his demon as a simple thought experiment to demonstrate his view that the second law of thermodynamics was not a law but a statistical effect. However, like many of the best thought-experiments in science, the demon’s influence was much broader: resolutions to the demon paradox became the foundations of two new fields: information theory and the physics of information.
Statistical Mechanics in a Nutshell
In an earlier section, I defined “entropy” as a measure of the energy that cannot be converted into additional work but is instead transformed into heat. This notion of entropy was originally defined by Rudolph Clausius in 1865. At the time of Clausius, heat was believed to be a kind of fluid that could move from one system to another, and temperature was a property of a system that affected the flow of heat.
In the next few decades, a different view of heat emerged in the scientific community: systems are made up of molecules, and heat is a result of the motion, or kinetic energy, of those molecules. This new view was largely a result of the work of Ludwig Boltzmann, who developed what is now called statistical mechanics.

Ludwig Boltzmann, 1844-1906 (AIP Emilio Segre Visual Archives, Segre Collection)
Statistical mechanics proposes that large-scale properties (e.g., heat) emerge from microscopic properties (e.g., the motions of trillions of molecules). For example, think about a room full of moving air molecules. A classicalmechanics analysis would determine the position and velocity of each molecule, as well as all the forces acting on that molecule, and would use this information to determine the future position and velocity of that molecule. Of course, if there are fifty quadrillion molecules, this approach would take rather a long time—in fact it always would be impossible, both in practice and, as quantum mechanics has shown, in principle. A statistical mechanics approach gives up on determining the exact position, velocity, and future behavior of each molecule and instead tries to predict the average positions and velocities of large ensembles of molecules.
In short, classical mechanics attempts to say something about every single microscopic entity (e.g., molecule) by using Newton’s laws. Thermodynamics gives laws of macroscopic entities—heat, energy, and entropy—without acknowledging that any microscopic molecules are the source of these macroscopic entities. Statistical mechanics is a bridge between these two extremes, in that it explains how the behavior of the macroscopic entities arise from statistics of large ensembles of microscopic entities.
There is one problem with the statistical approach—it gives only the probable behavior of the system. For example, if all the air molecules in a room are flying around randomly, they are most likely to be spread out all over the room, and all of us will have enough air to breathe. This is what we predict and depend on, and it has never failed us yet. However, according to statistical mechanics, since the molecules are flying around randomly, there is some very small chance that at some point they will all fly over to the same corner at the same time. Then any person who happened to be in that corner would be crushed by the huge air pressure, and the rest of us would suffocate from lack of air. As far as I know, such an event has never happened in any room anywhere. However, there is nothing in Newton’s laws that says it can’t happen; it’s just incredibly unlikely. Boltzmann reasoned that if there are enough microscopic entities to average over, his statistical approach will give the right answer virtually all the time, and indeed, in practice it does so. But at the time Boltzmann was formulating his new science, the suggestion that a physical law could apply only “virtually all of the time” rather than exactly all of the time was repellent to many other scientists. Furthermore, Boltzmann’s insistence on the reality of microscopic entities such as molecules and atoms was also at odds with his colleagues. Some have speculated that the rejection of his ideas by most of his fellow scientists contributed to his suicide in 1906, at the age of 62. Only years after his death were his ideas generally accepted; he is now considered to be one of the most important scientists in history.
Microstates and Macrostates
Given a room full of air, at a given instant in time each molecule has a certain position and velocity, even if it is impossible to actually measure all of them. In statistical mechanics terminology, the particular collection of exact molecule positions and velocities at a given instant is called the microstate of the whole room at that instant. For a room full of air molecules randomly flying around, the most probable type of microstate at a given time is that the air molecules are spread uniformly around the room. The least probable type of microstate is that the air molecules are all clumped together as closely as possible in a single location, for example, the corner of the room. This seems simply obvious, but Boltzmann noted that the reason for this is that there are many more possible microstates of the system in which the air molecules are spread around uniformly than there are microstates in which they all are clumped together.
The situation is analogous to a slot machine with three rotating pictures (figure 3.2). Suppose each of the three pictures can come up “apple,” “orange,” “cherry,” “pear,” or “lemon.” Imagine you put in a quarter, and pull the handle to spin the pictures. It is much more likely that the pictures will all be different (i.e., you lose your money) than that the pictures will all be the same (i.e., you win a jackpot). Now imagine such a slot machine with fifty quadrillion pictures, and you can see that the probability of all coming up the same is very close to zero, just like the probability of the air molecules ending up all clumped together in the same location.
FIGURE 3.2. Slot machine with three rotating fruit pictures, illustrating the concepts microstate and macrostate. (Drawing by David Moser.)
A type of microstate, for example, “pictures all the same—you win” versus “pictures not all the same—you lose” or “molecules clumped together—we can’t breathe” versus “molecules uniformly spread out—we can breathe,” is called a macrostate of the system. A macrostate can correspond to many different microstates. In the slot machine, there are many different microstates consisting of three nonidentical pictures, each of which corresponds to the single “you lose” macrostate, and only a few microstates that correspond to the “you win” macrostate. This is how casinos are sure to make money. Temperature is a macrostate—it corresponds to many different possible microstates of molecules at different velocities that happen to average to the same temperature.
Using these ideas, Boltzmann interpreted the second law of thermodynamics as simply saying that an isolated system will more likely be in a more probable macrostate than in a less probable one. To our ears this sounds like a tautology but it was a rather revolutionary way of thinking about the point back then, since it included the notion of probability. Boltzmann defined the entropy of a macrostate as a function of the number of microstates that could give rise to that macrostate. For example, on the slot machine of figure 3.2, where each picture can come up “apple,” “orange,” “cherry,” “pear,” or “lemon,” it turns out that there are a total of 125 possible combinations (microstates), out of which five correspond to the macrostate “pictures all the same—you win” and 120 correspond to the macrostate “pictures not all the same—you lose.” The latter macrostate clearly has a higher Boltzmann entropy than the former.
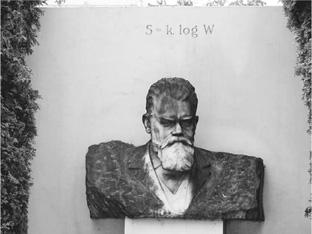
FIGURE 3.3. Boltzmann’s tombstone, in Vienna. (Photograph courtesy of Martin Roell.)
Boltzmann’s entropy obeys the second law of thermodynamics. Unless work is done, Boltzmann’s entropy will always increase until it gets to a macrostate with highest possible entropy. Boltzmann was able to show that, under many conditions, his simple and intuitive definition of entropy is equivalent to the original definition of Clausius.
The actual equation for Boltzmann’s entropy, now so fundamental to physics, appears on Boltzmann’s tombstone in Vienna (figure 3.3).
Shannon Information
Many of the most basic scientific ideas are spurred by advances in technology. The nineteenth-century studies of thermodynamics were inspired and driven by the challenge of improving steam engines. The studies of information by mathematician Claude Shannon were likewise driven by the twentieth-century revolution in communications—particularly the development of the telegraph and telephone. In the 1940s, Shannon adapted Boltzmann’s ideas to the more abstract realm of communications. Shannon worked at Bell Labs, a part of the American Telephone and Telegraph Company (AT&T). One of the most important problems for AT&T was to figure out how to transmit signals more quickly and reliably over telegraph and telephone wires.

Claude Shannon, 1916-2001. (Reprinted with permission of Lucent Technologies Inc./Bell Labs.)
Shannon’s mathematical solution to this problem was the beginning of what is now called information theory. In his 1948 paper “A Mathematical Theory of Communication,” Shannon gave a narrow definition of information and proved a very important theorem, which gave the maximum possible transmission rate of information over a given channel (wire or other medium), even if there are errors in transmission caused by noise on the channel. This maximum transmission rate is called the channel capacity.
Shannon’s definition of information involves a source that sends messages to a receiver. For example, figure 3.4 shows two examples of a source talking to a receiver on the phone. Each word the source says can be considered a message in the Shannon sense. Just as the telephone doesn’t understand the words being said on it but only transmits the electrical pulses used to encode the voice, Shannon’s definition of information completely ignores the meaningof the messages and takes into account only how often the source sends each of the possible different messages to the receiver.

FIGURE 3.4. Top: Information content (zero) of Nicky’s conversation with Grandma. Bottom: Higher information content of Jake’s conversation with Grandma. (Drawings by David Moser.)
Shannon asked, “How much information is transmitted by a source sending messages to a receiver?” In analogy with Boltzmann’s ideas, Shannon defined the information of a macrostate (here, a source) as a function of the number of possible microstates (here, ensembles of possible messages) that could be sent by that source. When my son Nicky was barely a toddler, I would put him on the phone to talk with Grandma. He loved to talk on the phone, but could say only one word—“da.” His messages to Grandma were “da da da da da….” In other words, the Nicky-macrostate had only one possible microstate (sequences of “da”s), and although the macrostate was cute, the information content was, well, zero. Grandma knew just what to expect. My son Jake, two years older, also loved to talk on the phone but had a much bigger vocabulary and would tell Grandma all about his activities, projects, and adventures, constantly surprising her with his command of language. Clearly the information content of the Jake-source was much higher, since so many microstates—i.e., more different collections of messages—could be produced.
Shannon’s definition of information content was nearly identical to Boltzmann’s more general definition of entropy. In his classic 1948 paper, Shannon defined the information content in terms of the entropy of the message source. (This notion of entropy is often called Shannon entropy to distinguish it from the related definition of entropy given by Boltzmann.)
People have sometimes characterized Shannon’s definition of information content as the “average amount of surprise” a receiver experiences on receiving a message, in which “surprise” means something like the “degree of uncertainty” the receiver had about what the source would send next. Grandma is clearly more surprised at each word Jake says than at each word Nicky says, since she already knows exactly what Nicky will say next but can’t as easily predict what Jake will say next. Thus each word Jake says gives her a higher average “information content” than each word Nicky says.
In general, in Shannon’s theory, a message can be any unit of communication, be it a letter, a word, a sentence, or even a single bit (a zero or a one). Once again, the entropy (and thus information content) of a source is defined in terms of message probabilities and is not concerned with the “meaning” of a message.
Shannon’s results set the stage for applications in many different fields. The best-known applications are in the field of coding theory, which deals with both data compression and the way codes need to be structured to be reliably transmitted. Coding theory affects nearly all of our electronic communications; cell phones, computer networks, and the worldwide global positioning system are a few examples.
Information theory is also central in cryptography and in the relatively new field of bioinformatics, in which entropy and other information theory measures are used to analyze patterns in gene sequences. It has also been applied to analysis of language and music and in psychology, statistical inference, and artificial intelligence, among many other fields. Although information theory was inspired by notions of entropy in thermodynamics and statistical mechanics, it is controversial whether or not information theory has had much of a reverse impact on those and other fields of physics. In 1961, communications engineer and writer John Pierce quipped that “efforts to marry communication theory and physics have been more interesting than fruitful.” Some physicists would still agree with him. However, there are a number of new approaches to physics based on concepts related to Shannon’s information theory (e.g., quantum information theory and the physics of information) that are beginning to be fruitful as well as interesting.
As you will see in subsequent chapters, information theoretic notions such as entropy, information content, mutual information, information dynamics, and others have played central though controversial roles in attempts to define the notion of complexity and in characterizing different types of complex systems.