Complexity: A Guided Tour - Melanie Mitchell (2009)
Part III. Computation Writ Large
Chapter 13. How to Make Analogies (if You Are a Computer)
Easy Things Are Hard
The other day I said to my eight-year-old son, “Jake, please put your socks on.” He responded by putting them on his head. “See, I put my socks on!” He thought this was hilarious. I, on the other hand, realized that his antics illustrated a deep truth about the difference between humans and computers.
The “socks on head” joke was funny (at least to an eight-year-old) because it violates something we all know is true: even though most statements in human language are, in principle, ambiguous, when you say something to another person, they almost always know what you mean. If I say to my husband, “Honey, do you know where my keys are?” and he replies, simply, “yes,” I get annoyed—of course I meant “tell me where my keys are.” When my best friend says that she is feeling swamped at her job, and I reply “same here,” she knows that I don’t mean that I am feeling swamped at her job, but rather my own. This mutual understanding is what we might call “common sense” or, more formally, “sensitivity to context.”
In contrast, we have modern-day computers, which are anything but sensitive to context. My computer supposedly has a state-of-the-art spam filter, but sometimes it can’t figure out that a message with a “word” such as V!a&®@is likely to be spam. As a similar example, a recent New York Times article described how print journalists are now learning how to improve the Web accessibility of their stories by tailoring headlines to literal-minded search engines instead of to savvy humans: “About a year ago, the Sacramento Bee changed online section titles. ‘Real Estate’ became ‘Homes,’ ‘Scene’ turned into ‘Lifestyle,’ and dining information found in newsprint under ‘Taste,’ is online under ‘Taste/Food.’ ”
This is, of course, not to say that computers are dumb about everything. In selected, narrow domains they have become quite intelligent. Computer-controlled vehicles can now drive by themselves across rugged desert terrain. Computer programs can beat human doctors at diagnosing certain diseases, human mathematicians at solving complex equations, and human grand masters at chess. These are only a few examples of a surge of recent successes in artificial intelligence (AI) that have brought a new sense of optimism to the field. Computer scientist Eric Horvitz noted, “At conferences you are hearing the phrase ‘human-level AI,’ and people are saying that without blushing.”
Well, some people, perhaps. There are a few minor “human-level” things computers still can’t do, such as understand human language, describe the content of a photograph, and more generally use common sense as in the preceding examples. Marvin Minsky, a founder of the field of artificial intelligence, concisely described this paradox of AI as, “Easy things are hard.” Computers can do many things that we humans consider to require high intelligence, but at the same time they are unable to perform tasks that any three-year-old child could do with ease.
Making Analogies
An important missing piece for current-day computers is the ability to make analogies.
The term analogy often conjures up people’s bad memories of standardized test questions, such as “Shoe is to foot as glove is to _____?” However, what I mean by analogy-making is much broader: analogy-making is the ability to perceive abstract similarity between two things in the face of superficial differences. This ability pervades almost every aspect of what we call intelligence.
Consider the following examples:
A child learns that dogs in picture books, photographs, and real life are all instances of the same concept.
A person is easily able to recognize the letter A in a vast variety of printed typefaces and handwriting.
Jean says to Simone, “I call my parents once a week.” Simone replies “I do that too,” meaning, of course, not that she calls Jean’s parents once a week, but that she calls her own parents.
A woman says to her male colleague, “I’ve been working so hard lately, I haven’t been able to spend enough time with my husband.” He replies, “Same here”—meaning not that he is too busy to spend enough time with the woman’s husband, but that he has little time to spend with his girlfriend.
An advertisement describes Perrier as “the Cadillac of bottled waters.” A newspaper article describes teaching as “the Beirut of professions.” The war in Iraq is called “another Vietnam.”
Britain and Argentina go to war over the Falklands (or las Malvinas), a set of small islands located near the coast of Argentina and populated by British settlers. Greece sides with Britain because of its own conflict with Turkey over Cyprus, an island near the coast of Turkey, the majority of whose population is ethnically Greek.
A classical music lover hears an unfamiliar piece on the radio and knows instantly that it is by Bach. An early-music enthusiast hears a piece for baroque orchestra and can easily identify which country the composer was from. A supermarket shopper recognizes the music being piped in as a Muzak version of the Beatles’ “Hey Jude.”
The physicist Hideki Yukawa explains the nuclear force by using an analogy with the electromagnetic force, on which basis he postulates a mediating particle for the nuclear force with properties analogous to the photon. The particle is subsequently discovered, and its predicted properties are verified. Yukawa wins a Nobel prize.
This list is a small sampling of analogies ranging from the mundane everyday kind to the once-in-a-lifetime-discovery kind. Each of these examples demonstrates, at different levels of impressiveness, how good humans are at perceiving abstract similarity between two entities or situations by letting concepts “slip” from situation to situation in a fluid way. The list taken as a whole illustrates the ubiquity of this ability in human thought. As the nineteenth-century philosopher Henry David Thoreau put it, “All perception of truth is the detection of an analogy.”
Perceiving abstract similarities is something computers are notoriously bad at. That’s why I can’t simply show the computer a picture, say, of a dog swimming in a pool, and ask it to find “other pictures like this” in my online photo collection.
My Own Route to Analogy
In the early 1980s, after I had graduated from college and didn’t quite know what to do with my life, I got a job as a high-school math teacher in New York City. The job provided me with very little money, and New York is an expensive city, so I cut down on unnecessary purchases. But one purchase I did make was a relatively new book written by a computer science professor at Indiana University, with the odd title Gödel, Escher, Bach: an Eternal Golden Braid. Having majored in math and having visited a lot of museums, I knew who Gödel and Escher were, and being a fan of classical music, I knew very well who Bach was. But putting their names together in a book title didn’t make sense to me, and my curiosity was piqued.
Reading the book, written by Douglas Hofstadter, turned out to be one of those life-changing events that one can never anticipate. The title didn’t let on that the book was fundamentally about how thinking and consciousness emerge from the brain via the decentralized interactions of large numbers of simple neurons, analogous to the emergent behavior of systems such as cells, ant colonies, and the immune system. In short, the book was my introduction to some of the main ideas of complex systems.
It was clear that Hofstadter’s passionate goal was to use similar principles to construct intelligent and “self-aware” computer programs. These ideas quickly became my passion as well, and I decided that I wanted to study artificial intelligence with Hofstadter.

Douglas Hofstadter. (Photograph courtesy of Indiana University.)
The problem was, I was a young nobody right out of college and Hofstadter was a famous writer of a best-selling book that had won both a Pulitzer Prize and a National Book Award. I wrote him a letter saying I wanted to come work with him as a graduate student. Naturally, he never responded. So I settled for biding my time and learning a bit more about AI.
A year later I had moved to Boston with a new job and was taking classes in computer science to prepare for my new career. One day I happened to see a poster advertising a talk by Hofstadter at MIT. Excited, I went to the talk, and afterward mingled among the throng of fans waiting to meet their hero (I wasn’t the only one whose life was changed by Hofstadter’s book). I finally got to the front of the line, shook Hofstadter’s hand, and told him that I wanted to work in AI on ideas like his and that I was interested in applying to Indiana University. I asked if I could visit him sometime at Indiana to talk more. He told me that he was actually living in Boston, visiting the MIT Artificial Intelligence Lab for the year. He didn’t invite me to come talk to him at the AI Lab; rather he handed me off to talk to a former student of his who was hanging around, and quickly went on to the next person in line.
I was disappointed, but not deterred. I managed to find Hofstadter’s phone number at the MIT AI Lab, and called several times. Each time the phone was answered by a secretary who told me that Hofstadter was not in, but she would be glad to leave a message. I left several messages but received no response.
Then, one night, I was lying in bed pondering what to do next, when a crazy idea hit me. All my calls to Hofstadter had been in the daytime, and he was never there. If he was never there during the day, then when was he there? It must be at night! It was 11:00 p.m., but I got up and dialed the familiar number. Hofstadter answered on the first ring.
He seemed to be in a much better mood than he was at the lecture. We chatted for a while, and he invited me to come by his office the next day to talk about how I could get involved in his group’s research. I showed up as requested, and we talked about Hofstadter’s current project—writing a computer program that could make analogies.
Sometimes, having the personality of a bulldog can pay off.
Simplifying Analogy
One of Hofstadter’s great intellectual gifts is the ability to take a complex problem and simplify it in such a way that it becomes easier to address but still retains its essence, the part that made it interesting in the first place. In this case, Hofstadter took the problem of analogy-making and created a microworld that retained many of the problem’s most interesting features. The microworld consists of analogies to be made between strings of letters.
For example, consider the following problem: if abc changes to abd, what is the analogous change to ijk? Most people describe the change as something like “Replace the rightmost letter by its alphabetic successor,” and answer ijl. But clearly there are many other possible answers, among them:
· ijd (“Replace the rightmost letter by a d”—similar to Jake putting his socks “on”)
· ijk (“Replace all c’s by d’s; there are no c’s in ijk ”), and
· abd (“Replace any string by abd ”).
There are, of course, an infinity of other, even less plausible answers, such as ijxx (“Replace all c’s by d’s and each k by two x’s”), but almost everyone immediately views ijl as the best answer. This being an abstract domain with no practical consequences, I may not be able to convince you that ijl is a better answer than, say, ijd if you really believe the latter is better. However, it seems that humans have evolved in such a way as to make analogies in the real world that affect their survival and reproduction, and their analogy-making ability seems to carry over into abstract domains as well. This means that almost all of us will, at heart, agree that there is a certain level of abstraction that is “most appropriate,” and here it yields the answer ijl. Those people who truly believe that ijd is a better answer would probably, if alive during the Pleistocene, have been eaten by tigers, which explains why there are not many such people around today.
Here is a second problem: if abc changes to abd, what is the analogous change to iijjkk? The abc ⇒ abd change can again be described as “Replace the rightmost letter by its alphabetic successor,” but if this rule is applied literally to iijjkk it yields answer iijjkl, which doesn’t take into account the double-letter structure of iijjkk. Most people will answer iijjll, implicitly using the rule “Replace the rightmost group of letters by its alphabetic successor,” letting the concept letter of abc slip into the concept group of letters for iijjkk.
Another kind of conceptual slippage can be seen in the problem
abc ⇒ abd
kji ⇒ ?
A literal application of the rule “Replace the rightmost letter by its alphabetic successor” yields answer kjj, but this ignores the reverse structure of kji, in which the increasing alphabetic sequence goes from right to left rather than from left to right. This puts pressure on the concept rightmost in abc to slip to leftmost in kji, which makes the new rule “Replace the leftmost letter by its alphabetic successor,” yielding answer lji. This is the answer given by most people. Some people prefer the answer kjh, in which the sequence kji is seen as going from left to right but decreasing in the alphabet. This entails a slippage from “alphabetic successor” to “alphabetic predecessor,” and the new rule is “Replace the rightmost letter by its alphabetic predecessor.”
Consider
abc ⇒ abd
mrrjjj ⇒ ?
You want to make use of the salient fact that abc is an alphabetically increasing sequence, but how? This internal “fabric” of abc is a very appealing and seemingly central aspect of the string, but at first glance no such fabric seems to weave mrrjjj together. So either (like most people) you settle for mrrkkk (or possibly mrrjjk), or you look more deeply. The interesting thing about this problem is that there happens to be an aspect of mrrjjj lurking beneath the surface that, once recognized, yields what many people feel is a more satisfying answer. If you ignore the letters in mrrjjj and look instead at group lengths, the desired successorship fabric is found: the lengths of groups increase as “1-2-3.” Once this connection between abc and mrrjjj is discovered, the rule describing abc ⇒ abd can be adapted to mrrjjj as “Replace the rightmost group of letters by its length successor,” which yields “1-2-4” at the abstract level, or, more concretely, mrrjjjj.
Finally, consider
abc ⇒ abd
xyz ⇒ ?
At first glance this problem is essentially the same as the problem with target string ijk given previously, but there is a snag: Z has no successor. Most people answer xya, but in Hofstadter’s microworld the alphabet is not circular and therefore this answer is excluded. This problem forces an impasse that requires analogy-makers to restructure their initial view, possibly making conceptual slippages that were not initially considered, and thus to discover a different way of understanding the situation.
People give a number of different responses to this problem, including xy (“Replace the z by nothing at all”), xyd (“Replace the rightmost letter by a d”; given the impasse, this answer seems less rigid and more reasonable than did ijd for the first problem above), xyy (“If you can’t take the z’s successor, then the next best thing is to take its predecessor”), and several other answers. However, there is one particular way of viewing this problem that, to many people, seems like a genuine insight, whether or not they come up with it themselves. The essential idea is that abc and xyz are “mirror images”—xyzis wedged against the end of the alphabet, and abc is similarly wedged against the beginning. Thus the z in xyz and the a in abc can be seen to correspond, and then one naturally feels that the x and the c correspond as well. Underlying these object correspondences is a set of slippages that are conceptually parallel: alphabetic-first ⇒ alphabetic-last, rightmost ⇒ leftmost, and successor ⇒ predecessor. Taken together, these slippages convert the original rule into a rule adapted to the target string xyz: “Replace the leftmost letter by its predecessor.” This yields a surprising but strong answer: wyz.
It should be clear by now that the key to analogy-making in this microworld (as well as in the real world) is what I am calling conceptual slippage. Finding appropriate conceptual slippages given the context at hand is the essence of finding a good analogy.
Being a Copycat
Doug Hofstadter’s plan was for me to write a computer program that could make analogies in the letter-string world by employing the same kinds of mechanisms that he believed are responsible for human analogy-making in general. He already had a name for this (as yet nonexistent) program: “Copycat.” The idea is that analogy-making is a subtle form of imitation—for example, ijk needs to imitate what happened when abc changed to abd, using concepts relevant in its own context. Thus the program’s job was to be a clever and creative copycat.
I began working on this project at MIT in the summer of 1984. That fall, Hofstadter started a new faculty position at the University of Michigan in Ann Arbor. I also moved there and enrolled as a Ph.D. student. It took a total of six years of working closely with Doug for me to construct the program he envisioned—the devil, of course, is in the details. Two results came out of this: a program that could make human-like analogies in its microworld, and (finally) my Ph.D.
How to Do the Right Thing
To be an intelligent copycat, you first have to make sense of the object, event, or situation that you are “copycatting.” When presented with a situation with many components and potential relations among components, be it a visual scene, a friend’s story, or a scientific problem, how does a person (or how might a computer program) mentally explore the typically intractably huge number of possible ways of understanding what is going on and possible similarities to other situations?
The following are two opposite and equally implausible strategies, both to be rejected:
1. Some possibilities are a priori absolutely excluded from being explored. For example, after an initial scan of mrrjjj, make a list of candidate concepts to explore (e.g., letter, group of letters, successor, predecessor, rightmost) and rigidly stick to it. The problem with this strategy, of course, is that it gives up flexibility. One or more concepts not immediately apparent as relevant to the situation (e.g., group length) might emerge later as being central.
2. All possibilities are equally available and easy to explore, so one can do an exhaustive search through all concepts and possible relationships that would ever be relevant in any situation. The problem with this strategy is that in real life there are always too many possibilities, and it’s not even clear ahead of time what might constitute a possible concept for a given situation. If you hear a funny clacking noise in your engine and then your car won’t start, you might give equal weight to the possibilities that (a) the timing belt has accidentally come off its bearings or (b) the timing belt is old and has broken. If for no special reason you give equal weight to the third possibility that your next-door neighbor has furtively cut your timing belt, you are a bit paranoid. If for no special reason you also give equal weight to the fourth possibility that the atoms making up your timing belt have quantum-tunneled into a parallel universe, you are a bit of a crackpot. If you continue and give equal weight to every other possibility ... well, you just can’t, not with a finite brain. However, there is some chance you might be right about the malicious neighbor, and the quantum-tunneling possibility shouldn’t be forever excluded from your cognitive capacities or you risk missing a Nobel prize.
The upshot is that all possibilities have to be potentially available, but they can’t all be equally available. Counterintuitive possibilities (e.g., your malicious neighbor; quantum-tunneling) must be potentially available but must require significant pressure to be considered (e.g., you’ve heard complaints about your neighbor; you’ve just installed a quantum-tunneling device in your car; every other possibility that you have explored has turned out to be wrong).
The problem of finding an exploration strategy that achieves this goal has been solved many times in nature. For example, we saw this in chapter 12 in the way ant colonies forage for food: the shortest trails leading to the best food sources attain the strongest pheromone scent, and increasing numbers of ants follow these trails. However, at any given time, some ants are still following weaker, less plausible trails, and some ants are still foraging randomly, allowing for the possibility of new food sources to be found.
This is an example of needing to keep a balance between exploration and exploitation, which I mentioned in chapter 12. When promising possibilities are identified, they should be exploited at a rate and intensity related to their estimated promise, which is being continually updated. But at all times exploration for new possibilities should continue. The problem is how to allocate limited resources—be they ants, lymphocytes, enzymes, or thoughts—to different possibilities in a dynamic way that takes new information into account as it is obtained. Ant colonies have solved this problem by having large numbers of ants follow a combination of two strategies: continual random foraging combined with a simple feedback mechanism of preferentially following trails scented with pheromones and laying down additional pheromone while doing so.
The immune system also seems to maintain a near optimal balance between exploration and exploitation. We saw in chapter 12 how the immune system uses randomness to attain the potential for responding to virtually any pathogen it encounters. This potential is realized when an antigen activates a particular B cell and triggers the proliferation of that cell and the production of antibodies with increasing specificity for the antigen in question. Thus the immune system exploits the information it encounters in the form of antigens by allocating much of its resources toward targeting those antigens that are actually found to be present. But it always continues to explore additional possibilities that it might encounter by maintaining its huge repertoire of different B cells. Like ant colonies, the immune system combines randomness with highly directed behavior based on feedback.
Hofstadter proposed a scheme for exploring uncertain environments: the “parallel terraced scan,” which I referred to in chapter 12. In this scheme many possibilities are explored in parallel, each being allocated resources according to feedback about its current promise, whose estimation is updated continually as new information is obtained. Like in an ant colony or the immune system, all possibilities have the potential to be explored, but at any given time only some are being actively explored, and not with equal resources. When a person (or ant colony or immune system) has little information about the situation facing it, the exploration of possibilities starts out being very random, highly parallel (many possibilities being considered at once) and unfocused: there is no pressure to explore any particular possibility more strongly than any other. As more and more information is obtained, exploration gradually becomes more focused (increasing resources are concentrated on a smaller number of possibilities) and less random: possibilities that have already been identified as promising are exploited. As in ant colonies and the immune system, in Copycat such an exploration strategy emerges from myriad interactions among simple components.
Overview of the Copycat Program
Copycat’s task is to use the concepts it possesses to build perceptual structures—descriptions of objects, links between objects in the same string, groupings of objects in a string, and correspondences between objects in different strings—on top of the three “raw,” unprocessed letter strings given to it in each problem. The structures the program builds represent its understanding of the problem and allow it to formulate a solution. Since for every problem the program starts out from exactly the same state with exactly the same set of concepts, its concepts have to be adaptable, in terms of their relevance and their associations with one another, to different situations. In a given problem, as the representation of a situation is constructed, associations arise and are considered in a probabilistic fashion according to a parallel terraced scan in which many routes toward understanding the situation are tested in parallel, each at a rate and to a depth reflecting ongoing evaluations of its promise.
Copycat’s solution of letter-string analogy problems involves the interaction of the following components:
· The Slipnet: A network of concepts, each of which consists of a central node surrounded by potential associations and slippages. A picture of some of the concepts and relationships in the current version of the program is given in figure 13.1. Each node in the Slipnet has a dynamic activation value that gives its current perceived relevance to the analogy problem at hand, which therefore changes as the program runs. Activation also spreads from a node to its conceptual neighbors and decays if not reinforced. Each link has a dynamic resistance value that gives its current resistance to slippage. This also changes as the program runs. The resistance of a link is inversely proportional to the activation of the node naming the link. For example, when opposite is highly active, the resistance to slippage between nodes linked by opposite links (e.g., successor and predecessor) is lowered, and the probability of such slippages is increased.
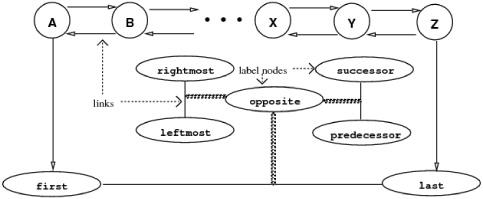
FIGURE 13.1. Part of Copycat’s Slipnet. Each node is labeled with the concept it represents (e.g., A-Z, rightmost, successor). Some links between nodes (e.g., rightmost-leftmost) are connected to a label node giving the link’s relationship (e.g., opposite). Each node has a dynamic activation value (not shown) and spreads activation to neighboring nodes. Activation decays if not reinforced. Each link has an intrinsic resistance to slippage, which decreases when the label node is activated.
· The Workspace: A working area in which the letters composing the analogy problem reside and in which perceptual structures are built on top of the letters.
· Codelets: Agents that continually explore possibilities for perceptual structures to build in the Workspace, and, based on their findings, attempt to instantiate such structures. (The term codelet is meant to evoke the notion of a “small piece of code,” just as the later term applet in Java is meant to evoke the notion of a small application program.) Teams of codelets cooperate and compete to construct perceptual structures defining relationships between objects (e.g., “b is the successor of a in abc,” or “the two i’s in iijjkk form a group,” or “the b in abc corresponds to the group of j’s in iijjkk,” or “the c in abc corresponds to the k in kji ”). Each team considers a particular possibility for structuring part of the world, and the resources (codelet time) allocated to each team depends on the promise of the structure it is trying to build, as assessed dynamically as exploration proceeds. In this way, a parallel terraced scan of possibilities emerges as the teams of codelets, via competition and cooperation, gradually build up a hierarchy of structures that defines the program’s “understanding” of the situation with which it is faced.
· Temperature, which measures the amount of perceptual organization in the system. As in the physical world, high temperature corresponds to disorganization, and low temperature corresponds to a high degree of organization. In Copycat, temperature both measures organization and feeds back to control the degree of randomness with which codelets make decisions. When the temperature is high, reflecting little perceptual organization and little information on which to base decisions, codelets make their decisions more randomly. As perceptual structures are built and more information is obtained about what concepts are relevant and how to structure the perception of objects and relationships in the world, the temperature decreases, reflecting the presence of more information to guide decisions, and codelets make their decisions more deterministically.
A Run of Copycat
The best way to describe how these different components interact in Copycat is to display graphics from an actual run of the program. These graphics are produced in real-time as the program runs. This section displays snapshots from a run of the program on abc ⇒ abd, mrrjjj ⇒ ?
Figure 13.2: The problem is presented. Displayed are: the Workspace (here, the as-yet unstructured letters of the analogy problem); a “thermometer” on the left that gives the current temperature (initially set at 100, its maximum value, reflecting the lack of any perceptual structures); and the number of codelets that have run so far (zero).
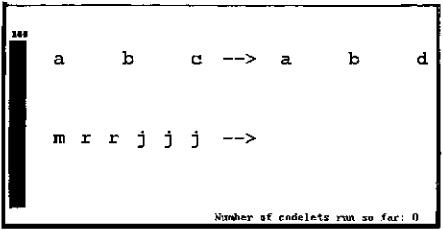
FIGURE 13.2.
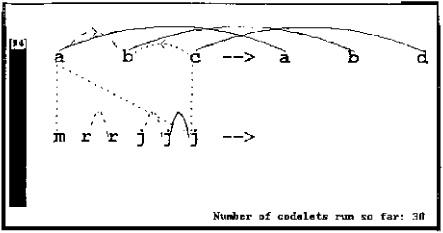
FIGURE 13.3.
Figure 13.3: Thirty codelets have run and have investigated a variety of possible structures. Conceptually, codelets can be thought of as antlike agents, each one probabilistically following a path to explore but being guided by the paths laid down by other codelets. In this case the “paths” correspond to candidate perceptual structures. Candidate structures are proposed by codelets looking around at random for plausible descriptions, relationships, and groupings within strings, and correspondences between strings. A proposed structure becomes stronger as more and more codelets consider it and find it worthwhile. After a certain threshold of strength, the structure is considered to be “built” and can then influence subsequent structure building.
In figure 13.3, dotted lines and arcs represent structures in early stages of consideration; dashed lines and arcs represent structures in more serious stages of consideration; finally, solid lines and arcs represent structures that have been built. The speed at which proposed structures are considered depends on codelets’ assessments of the promise of the structure. For example, the codelet that proposed the a-m correspondence rated it as highly promising because both objects are leftmost in their respective strings: identity relationships such as leftmost ⇒ leftmost are always strong. The codelet that proposed the a-j correspondence rated it much more weakly, since the mapping it is based on, leftmost ⇒ rightmost, is much weaker, especially given that opposite is not currently active. Thus the a-m correspondence is likely to be investigated more quickly than the less plausible a-j correspondence.
The temperature has gone down from 100 to 94 in response to the single built structure, the “sameness” link between the rightmost two j’s in mrrjjj. This sameness link activated the node same in the Slipnet (not shown), which creates focused pressure in the form of specifically targeted codelets to look for instances of sameness elsewhere.
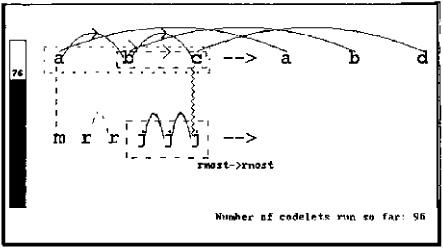
FIGURE 13.4.
Figure 13.4: Ninety-six codelets have run. The successorship fabric of abc has been built. Note that the proposed c-to-b predecessor link of figure 13.3 has been out-competed by a successor link. The two successor links in abcsupport each other: each is viewed as stronger due to the presence of the other, making rival predecessor links much less likely to destroy the successor links.
Two rival groups based on successorship links between letters are being considered: bc and abc (a whole-string group). These are represented by dotted or dashed rectangles around the letters in figure 13.4. Although bc got off to an early lead (it is dashed while the latter is only dotted), the group abc covers more objects in the string. This makes it stronger than bc—codelets will likely get around to testing it more quickly and will be more likely to build it than to build bc. A strong group, jjj, based on sameness is being considered in the bottom string.
Exploration of the crosswise a-j correspondence (dotted line in figure 13.3) has been aborted, since codelets that further investigated it found it too weak to be built. A c-j correspondence has been built (jagged vertical line); the mapping on which it is based (namely, both letters are rightmost in their respective strings) is given beneath it.
Since successor and sameness links have been built, along with an identity mapping (rightmost ⇒ rightmost), these nodes are highly active in the Slipnet and are creating focused pressure in the form of codelets to search explicitly for other instances of these concepts. For example, an identity mapping between the two leftmost letters is being considered.
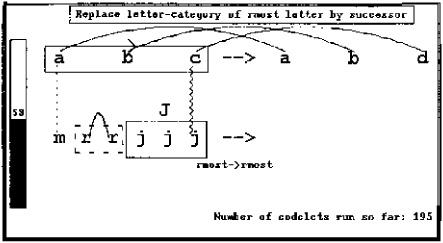
FIGURE 13.5.
In response to the structures that have been built, the temperature has decreased to 76. The lower the temperature, the less random are the decisions made by codelets, so unlikely structures such as the bc group are even more unlikely to be built.
Figure 13.5: The abc and jjj groups have been built, represented by solid rectangles around the letters. For graphical clarity, the links between letters in a group are not displayed. The existence of these groups creates additional pressure to find new successorship and sameness groups, such as the rr sameness group that is being strongly considered. Groups, such as the jjj sameness group, become new objects in the string and can have their own descriptions, as well as links and correspondences to other objects. The capital J represents the object consisting of the jjj group; the abc group likewise is a new object but for clarity a single letter representing it is not displayed. Note that the length of a group is not automatically noticed by the program; it has to be noticed by codelets, just like other attributes of an object. Every time a group node (e.g., successor group, sameness group) is activated in the Slipnet, it spreads some activation to the node length. Thus length is now weakly activated and creating codelets to notice lengths, but these codelets are not urgent compared with others and none so far have run and noticed the lengths of groups.
A rule describing the abc ⇒ abd change has been built: “Replace letter-category of rightmost letter by successor.” The current version of Copycat assumes that the example change consists of the replacement of exactly one letter, so rule-building codelets fill in the template “Replace _______ by _______,” choosing probabilistically from descriptions that the program has attached to the changed letter and its replacement, with a probabilistic bias toward choosing more abstract descriptions (e.g., usually preferring rightmost letter to C).
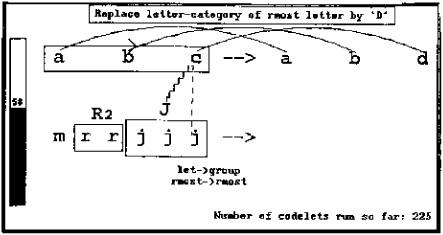
FIGURE 13.6.
The temperature has fallen to 53, resulting from the increasing perceptual organization reflected in the structures that have been built.
Figure 13.6: Two-hundred twenty-five codelets have run. The letter-to-letter c-j correspondence has been defeated by the letter-to-group c-J correspondence. Reflecting this, the rightmost ⇒ rightmost mapping has been joined by a letter ⇒ group mapping underlying the correspondence. The c-J correspondence is stronger than the c-j correspondence because the former covers more objects and because the concept group is highly active and thus seen as highly relevant to the problem. However, in spite of its relative weakness, the c-j correspondence is again being considered by a new team of codelets.
Meanwhile, the rr group has been built. In addition, its length (represented by the 2 next to the R) has been noticed by a codelet (a probabilistic event). This event activated the node length, creating pressure to notice other groups’ lengths.
A new rule, “Replace the letter category of the rightmost letter by ‘D,’ ” has replaced the old one at the top of the screen. Although this rule is weaker than the previous one, competitions between rival structures (including rules) are decided probabilistically, and this one simply happened to win. However, its weakness has caused the temperature to increase to 58.
If the program were to stop now (which is quite unlikely, since a key factor in the program’s probabilistic decision to stop is the temperature, which is still relatively high), the rule would be adapted for application to the string mrrjjj as “Replace the letter category of the rightmost group by ‘D,’ ” obeying the slippage letter ⇒ group spelled out under the c-J correspondence. This yields answer mrrddd, an answer that Copycat does indeed produce, though on very rare occasions.
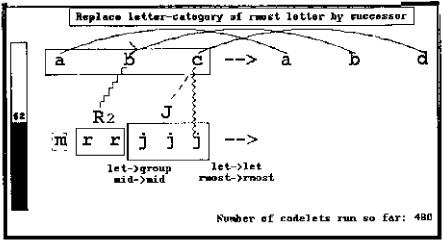
FIGURE 13.7.
Codelets that attempt to create an answer run frequently throughout the program (their attempts are not displayed here) but are not likely to succeed unless the temperature is low.
Figure 13.7: Four hundred eighty codelets into the run, the rule “Replace letter-category of rightmost letter by successor” has been restored after it out-competed the previous weaker rule (a probabilistic event). However, the strong c-J correspondence was broken and replaced by its weaker rival, the c-j correspondence (also a probabilistic event). As a consequence, if the program were to stop at this point, its answer would be mrrjjk, since the c in abcis mapped to a letter, not to a group. Thus the answer-building codelet would ignore the fact that b has been mapped to a group. However, the (now) candidate correspondence between the c and the group J is again being strongly considered. It will fight again with the c-j correspondence, but will likely be seen as even stronger than before because of the parallel correspondence between the b and the group R.
In the Slipnet the activation of length has decayed since the length description given to the R group hasn’t so far been found to be useful (i.e., it hasn’t yet been connected up with any other structures). In the Workspace, the salience of the group R’s length description 2 is correspondingly diminished.
The temperature is still fairly high, since the program is having a hard time making a single, coherent structure out of mrrjjj, something that it did easily with abc. That continuing difficulty, combined with strong focused pressure from the two sameness groups that have been built inside mrrjjj, caused the system to consider the a priori very unlikely idea of making a single-letter sameness group. This is represented by the dashed rectangle around the letter m.
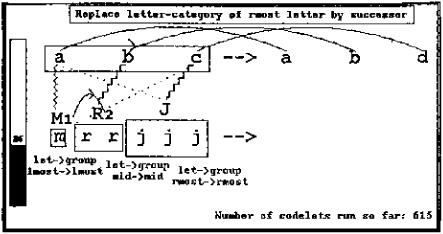
FIGURE 13.8.
Figure 13.8: As a result of these combined pressures, the M sameness group was built to parallel the R and J groups in the same string. Its length of 1 has been attached as a description, activating length, which makes the program again consider the possibility that group length is relevant for this problem. This activation now more strongly attracts codelets to the objects representing group lengths. Some codelets have already been exploring relations between these objects and, probably due to focused pressures from abc to see successorship relationships, have built a successorship link between the 1 and the 2.
A consistent trio of letter ⇒ group correspondences have been made, and as a result of these promising new structures the temperature has fallen to the relatively low value of 36, which in turn helps to lock in this emerging view.
If the program were to halt at this point, it would produce the answer mrrkkk, which is its most frequent answer (see figure 13.12).
Figure 13.9: As a result of length’s continued activity, length descriptions have been attached to the remaining two groups in the problem, jjj and abc, and a successorship link between the 2 and the 3 (for which there is much focused pressure coming from both abc and the emerging view of mrrjjj) is being considered. Other less likely candidate structures (a bc group and a c-j correspondence) continue to be considered, though at considerably less urgency than earlier, now that a coherent perception of the problem is emerging and the temperature is relatively low.
Figure 13.10: The link between the 2 and the 3 was built, which, in conjunction with focused pressure from the abc successor group, allowed codelets to propose and build a whole-string group based on successorship links, here between numbers rather than between letters. This group is represented by a large solid rectangle surrounding the three sameness groups. Also, a correspondence (dotted vertical line to the right of the two strings) is being considered between the two whole-string groups abc and mrrjjj.
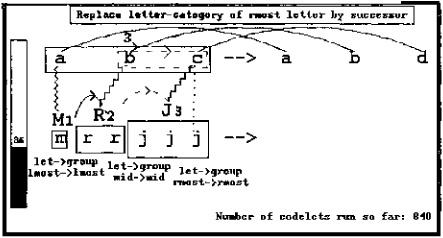
FIGURE 13.9.
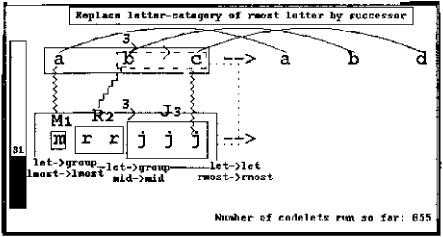
FIGURE 13.10.
Ironically, just as these sophisticated ideas seem to be converging, a small renegade codelet, totally unaware of the global movement, has had some good luck: its bid to knock down the c-J correspondence and replace it with a c-j correspondence was successful. Of course, this is a setback on the global level; while the temperature would have gone down significantly because of the strong mrrjjj group that was built, its decrease was offset by the now nonparallel set of correspondences linking together the two strings. If the program were forced to stop at this point, it would answer mrrjjk, since at this point, the object that changed, the c, is seen as corresponding to the letter j rather than the group J. However, the two other correspondences will continue to put much pressure on the program (in the form of codelets) to go back to the c-J correspondence.
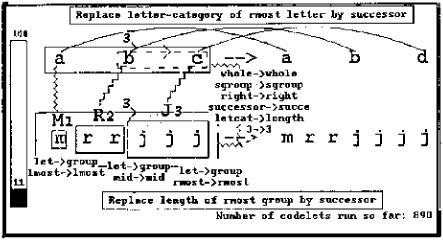
FIGURE 13.11.
Figure 13.11: Indeed, not much later in the run this happens: the c-j correspondence has been broken and the c-J correspondence has been restored. In addition, the proposed whole-string correspondence between abc and mrrjjjhas been built; underlying it are the mappings whole ⇒ whole, successor-group ⇒ successor-group, right ⇒ right (direction of the links underlying both groups), successor ⇒ successor (type of links underlying both groups), letter-category ⇒ length, and 3 ⇒ 3 (size of both groups).
The now very coherent set of perceptual structures built by the program resulted in a very low temperature (11), and (probabilistically) due to this low temperature, a codelet has succeeded in translating the rule according to the slippages present in the Workspace: letter ⇒ group and letter-category ⇒ length (all other mappings are identity mappings). The translated rule is “Replace the length of the rightmost group by its successor,” and the answer is thus mrrjjjj.
It should be clear from the description above that because each run of Copycat is permeated with probabilistic decisions, different answers appear on different runs. Figure 13.12 displays a bar graph showing the different answers Copycat gave over 1,000 runs, each starting from a different random number seed. Each bar’s height gives the relative frequency of the answer it corresponds to, and printed above each bar is the actual number of runs producing that answer. The average final temperature for each answer is also given below each bar’s label.
The frequency of an answer roughly corresponds to how obvious or immediate it is, given the biases of the program. For example, mrrkkk, produced 705 times, is much more immediate to the program than mrrjjjj, which was produced only 42 times. However, the average final temperature on runs producing mrrjjjj is much lower than on runs producing mrrkkk (21 versus 43), indicating that even though the latter is a more immediate answer, the program judges the former to be a better answer, in terms of the strength and coherence of the structures it built to produce each answer.
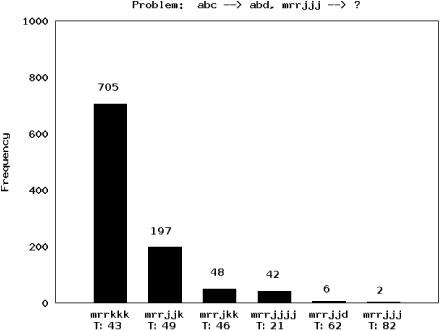
FIGURE 13.12. A bar graph plotting the different answers Copycat gave over 1,000 runs, each starting from a different random number seed.
Summary
Via the mechanisms illustrated in this run of the program, Copycat avoids the Catch-22 of perception: you can’t explore everything, but you don’t know which possibilities are worth exploring without first exploring them. You have to be open-minded, but the territory is too vast to explore everything; you need to use probabilities in order for exploration to be fair. In Copycat’s biologically inspired strategy, early on there is little information, resulting in high temperature and high degree of randomness, with lots of parallel explorations. As more and more information is obtained and fitting concepts are found, the temperature falls, and exploration becomes more deterministic and more serial as certain concepts come to dominate. The overall result is that the system gradually changes from a mostly random, parallel, bottom-up mode of processing to a deterministic, serial, focused mode in which a coherent perception of the situation at hand is gradually discovered and gradually “frozen in.” As I illustrated in chapter 12, this gradual transition between different modes of processing seems to be a feature common to at least some complex adaptive systems.
Analogies such as those between Copycat and biological systems force us to think more broadly about the systems we are building or trying to understand. If one notices, say, that the role of cytokines in immune signaling is similar to that of codelets that call attention to particular sites in an analogy problem, one is thinking at a general information-processing level about the function of a biological entity. Similarly, if one sees that temperature-like phenomena in the immune system—fever, inflammation—emerge from the joint actions of many agents, one might get some ideas on how to better model temperature in a system like Copycat.
Finally, there is the ever-thorny issue of meaning. In chapter 12 I said that for traditional computers, information is not meaningful to the computer itself but to its human creators and “end users.” However, I would like to think that Copycat, which represents a rather nontraditional mode of computation, perceives a very primitive kind of meaning in the concepts it has and in analogies it makes. For example, the concept successor group is embedded in a network in which it is linked to conceptually similar concepts, and Copycat can recognize and use this concept in an appropriate way in a large variety of diverse situations. This is, in my mind, the beginning of meaning. But as I said in chapter 12, meaning is intimately tied up with survival and natural selection, neither of which are relevant to Copycat, except for the very weak “survival” instinct of lowering its temperature. Copycat (and an even more impressive array of successor programs created in Hofstadter’s research group) is still quite far from biological systems in this way.
The ultimate goal of AI is to take humans out of the meaning loop and have the computer itself perceive meaning. This is AI’s hardest problem. The mathematician Gian-Carlo Rota called this problem “the barrier of meaning”and asked whether or when AI would ever “crash” it. I personally don’t think it will be anytime soon, but if and when this barrier is unlocked, I suspect that analogy will be the key.