BioBuilder: Synthetic Biology in the Lab (2015)
Chapter 1. Fundamentals of Synthetic Biology
Welcome to the BioBuilder program! We are thrilled that you want to bring the tools of synthetic biology into your classroom. Online, we have a variety of materials to help you get started, including some practical lab video tutorials, Microsoft PowerPoint slides, curriculum guides, and lab worksheets. In this written manual, we introduce foundational ideas that underlie synthetic biology, some key aspects of biology that are explored in the field and in the BioBuilder labs, and some helpful information to use as you run the experiments in the BioBuilder program.
In this chapter, we introduce the basic concepts of synthetic biology, explain how it differs from traditional biochemistry and genetic engineering, and begin to explore some of the fundamental engineering principles that will inform how we can solve problems using synthetic biology.
What Is Synthetic Biology?
At the most basic level, synthetic biologists, or biobuilders, want to engineer living cells to do something useful; for example, treat a disease, sense a toxic compound in the environment, or produce a valuable drug. As Figure 1-1 suggests, synthetic biologists achieve these outcomes by altering an organism’s DNA so that it behaves “according to specification,” as engineers say—basically, so it does what the biobuilder wants.
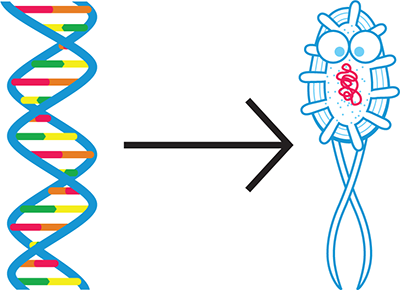
Figure 1-1. The goal of synthetic biology. Synthetic biology aims to write DNA (left) that instructs a cell or organism (right) to behave according to design specifications.
We can think of cells as complex miniature factories. The DNA provides instructions to make all the machines in the factory—proteins, other nucleic acids, multicomponent macromolecular complexes, and more. These “machines” then carry out the work of the cell. The organism’s naturally occurring DNA allows the cell to meet its basic survival and reproductive needs. Synthetic biologists can change a cell’s DNA so that the cell takes on new, useful functions (Figure 1-2). We’ll talk more about how researchers alter an organism’s DNA later in the chapter.
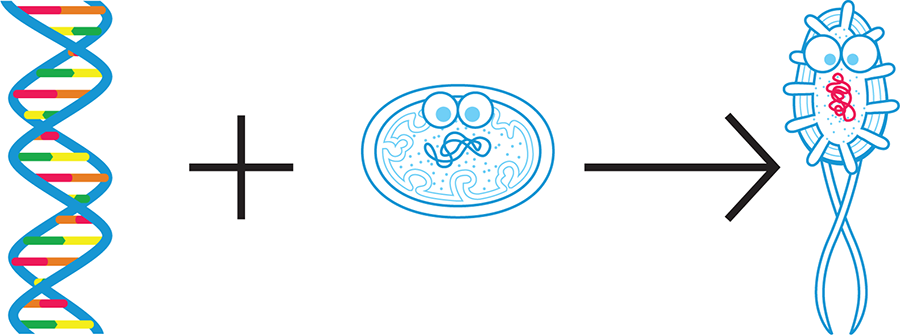
Figure 1-2. Synthetic biology today. Currently, synthetic biologists generally design a portion of DNA (left) and combine it with an existing cell or organism (middle) so that the new cell or organism (right) behaves according to design specifications.
Ultimately, synthetic biologists would like to be able to build specialized living organisms from scratch using designed DNA. The field isn’t there yet. Currently, most endeavors involve the modification of organisms that already exist rather than building all-new organisms to behave in novel ways.
Why Synthetic Biology?
Many of the challenges that synthetic biologists are targeting can be addressed by other engineering disciplines, such as electrical, chemical, or mechanical engineering, but synthetic biology’s solutions offer a few unique advantages.
Most strikingly, cells can make copies of themselves. Cars can’t copy themselves—you need a factory to build a car. Also, some organisms can copy themselves incredibly quickly, even with minimal nutrients. For example, in the lab, the bacterium E. coli can replicate and divide in about 30 minutes. Therefore, synthetic biology is an attractive approach for producing large amounts of a specific product because we can grow a programmed cell relatively easily to meet large-scale production demands. Cells serve as the physical factory for production, as well, providing much of the “bricks and mortar” infrastructure that would be required by other engineering solutions to meet the same challenge. Finally, the use of rapidly dividing cells also facilitates prototyping and testing, which are very important for the design cycle, which we’ll discuss in more detail a little later.
Second, cells contain the biological machinery to carry out many complex tasks—specific chemical reactions, for example—that would be difficult, if not impossible, to accomplish otherwise. And, they do so with nanoscale precision that is difficult to replicate in any traditional fabrication facility. Also, when their nanoscale machinery breaks, cells have mechanisms to repair themselves, at least to some extent, which puts them at a great advantage over more typical factory-based production processes. Cellular complexity introduces its own hurdles to be considered, as well, but its potential utility is enormous.
Third, synthetic biology has the potential to produce eco-friendly solutions to many difficult problems. By necessity, the byproducts of synthetic biology applications are generally nontoxic, because most toxic compounds would kill the very cells that are doing the work. In addition, harnessing natural cellular systems often results in economical processes. Today’s industrial production of compounds consume large quantities of energy, often creating significant amounts of environmentally harmful waste and frequently requiring high temperatures or pressures.
Beyond its usefulness for addressing real-world challenges, synthetic biology is also a fantastic approach to learn more about the workings of natural systems. As researchers dissect increasingly complex cellular functions, they can use synthetic biology to test their hypotheses from additional angles. For example, if their biochemical research results suggest that a certain protein acts as a sort of on/off switch, they can test this result by replacing the existing protein with a protein that is known to exhibit on/off behavior. If the new synthetic system and the natural system behave similarly, the result provides further evidence that the natural protein acts as the researchers suspected.
You might wonder: do we know enough about cells to reliably engineer them, and if not, should we really be trying? There are many justifiable fears and concerns unique to synthetic biology. Granted, other inventions such as the light bulb and the telegraph were engineered without full understanding of the physics of electricity, but engineering life has additional practical, moral, and ethical challenges beyond those faced in traditional engineering fields. For instance, evolution can mutate DNA that has been painstakingly programmed, ruining a cell’s engineered function. Replication of synthetic cells in the environment might pose a hazard if they interact in unexpected ways with existing organisms in that ecosystem. And, synthetic biology raises philosophical questions as we begin to think about cells as tiny living machines built to do our bidding. Any technology that asks us to reconsider our interaction with the natural world must be approached carefully. Researchers, bioethicists, and government organizations are actively discussing these issues and working to develop synthetic biology in responsible ways that will improve the living world. We explore these issues in more depth in the Fundamentals of Bioethics chapter.
We are still in the early days of this developing discipline. As described earlier, synthetic biologists are not yet able to make organisms from scratch; at present, they are working primarily within the framework of existing organisms. Also, research so far has been conducted primarily on relatively simple unicellular organisms such as bacteria (especially E. coli) and yeast (S. cerevisiae), although there have also been some early successes in more complex systems like plants and mammalian cells. As the field grows, though, engineering increasingly complex systems will expand even further the potential applications and benefits of synthetic biology.
Synthetic Biology in Context
The synthetic biology approach might remind you of genetic engineering, in which researchers make small-scale rational changes to an organism’s genome—such as removing a gene from a mouse or adding a human gene to a fruit fly—to study the system’s behavior. Synthetic biologists use many of the same tools that genetic engineers do, as we will discuss in more detail later, but synthetic biology and genetic engineering differ in the scale at which they aim to make these changes. Genetic engineers are usually introducing one or two small changes to investigate a specific system, whereas synthetic biologists aim to design new genomes and redesign existing genomes at a grand scale. An illustrative—albeit fanciful—example of synthetic biology’s potential scale is the genetic reprogramming of a tree so that it will grow into a fully functional house based on the genetic instructions designed by a synthetic biologist. Such a system would take advantage of the tree’s natural program (to grow by taking in a few nutrients from the environment) and put it to use for society’s needs. Genetically programming a tree to grow into a house, however, is far beyond the scale of traditional genetic engineering as well as the capacity of synthetic biology at this point.

To accomplish such large-scale design goals, synthetic biologists are establishing a structured engineering and design discipline, the principles of which we will introduce in the next section. Synthetic biologists are also drawing on the rich knowledge regarding how biological systems work that biochemists, molecular biologists, and geneticists have obtained over many years. Specifically, scientific research has yielded:
§ Reasonably well-characterized model systems, such as E. coli, yeast, algae, and various types of mammalian cell culture, that offer a solid foundation for synthetic biology exploration
§ Bountiful sequence data from a huge array of organisms, including bacteria, humans, mosquitoes, chickens, lions, mice, and many, many more, as well as tools for sequence comparison and analysis
§ The molecular tools to move, reorder, and synthesize DNA to create new sequences
Synthetic biologists use these discoveries and successes as a foundation to which they can apply an engineering mindset to solve real-world problems. The interdisciplinary nature of synthetic biology is suggested by Figure 1-3.
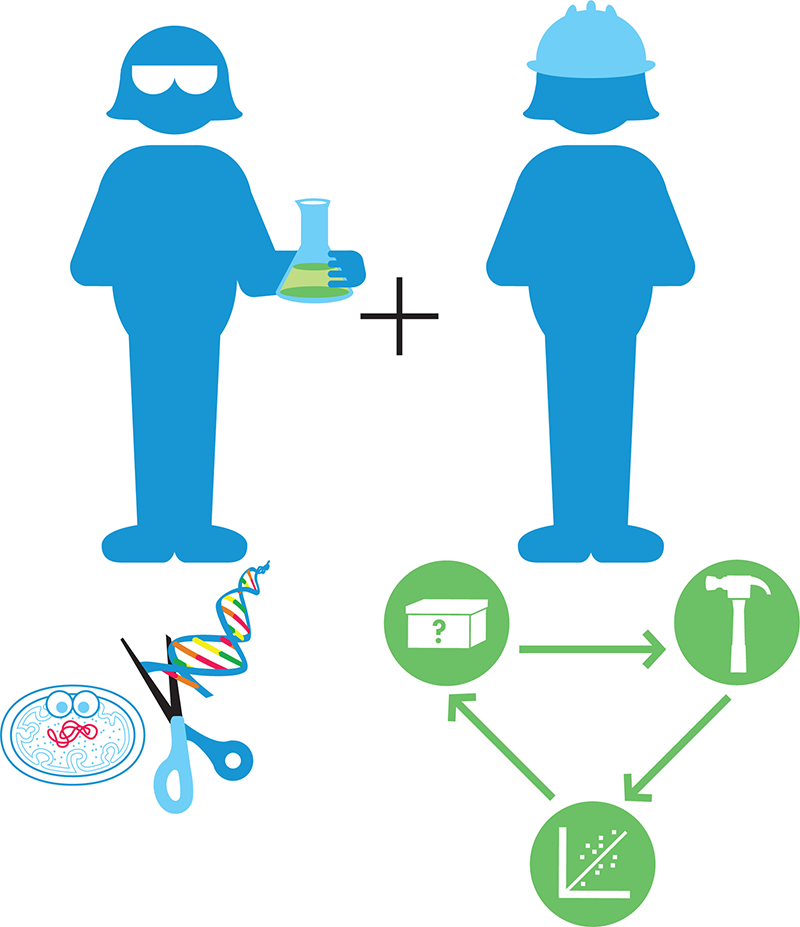
Figure 1-3. The interdisciplinary nature of synthetic biology. Synthetic biologists combine the wealth of knowledge and techniques from molecular biology (left) with engineering principles (right), including the design-build-test cycle that’s a hallmark of engineering disciplines.
Introduction to Engineering and Design
Engineers build complex systems that must behave consistently, according to the design specifications. To accomplish their goals engineers cycle through design, building, and testing phases, often doing rapid prototyping of different designs to find the most promising direction. This procedure resembles the scientific method, in which the researcher cycles through hypotheses, experiments, and analysis. The primary difference is that the scientific method aims to understand the precise details of how something works, whereas the engineering approach will not focus on why a design works as long as the prototype tests successfully. These differences are discussed in more depth in the Fundamentals of Biodesign chapter.
Here, we introduce a very simple example to show how different types of engineers might solve a problem: watering houseplants. By considering how different engineering disciplines might address this problem, we will introduce some design fundamentals and illustrate how synthetic biologists apply a similar mindset and approach.
“Traditional” Engineering Solutions
Some people naturally have a green thumb, but others need some extra help; otherwise, their plants end up looking dried and shriveled. Different types of engineers would approach this plant watering problem differently, depending on their expertise. For example, a mechanical engineer might design a pot with an unevenly weighted round bottom. When the reservoir in the bottom is full of water it acts as a counterweight and keeps the pot standing straight. As the plant absorbs the water, the counterweight decreases and the pot begins to tip over. This visual indicator would be an obvious reminder to the owner that the plant needs water. Perhaps the leaning plant could even turn on a faucet to water itself. By engineering feedback into the system, the pot would stand back up when the plant was watered, creating a closed-loop control system.

One potential complication with this design is that some plants require more water than others, so the designers might need to create many different pots with different weights in the bottom, and the gardeners would need to make sure they are buying the correct pot for their plant. These types of considerations are integral to the design process. No design is perfect, and it is important to understand the strengths as well as the limitations of any proposed design when considering the best way to proceed.
An electrical engineer might come up with a completely different solution to the watering problem, one involving electrical moisture sensors and automatic watering. Her system might consist of many electronic parts: wires, resistors, capacitors, moisture sensors, circuit boards, and more. The different parts could work together to monitor the system, determine when the plants need water, and then deliver that water when needed.

This electrical engineering solution requires standardization, a crucial principle in all engineering fields and one we will return to later in this chapter. In this plant watering example, each standardized electronic component was defined by the particular independent function it could carry out. The components were built to meet a set of industry standards. This standardization of basic parts makes it possible for them to be connected to one another easily and reliably, without the context affecting their behavior. Such standardizations simplify design, allowing engineers to know how a certain piece will behave and how it can be combined with other parts to yield a desired result. It also simplifies manufacturing, enabling factories to produce millions of identical resistors for millions of different products. Synthetic biology has not yet achieved this level of standardization but is trying to move in that direction.
Engineering Toolkits
These two examples of traditional engineering solutions to the plant watering challenge illustrate how multiple designs can be used to solve even a relatively simple problem. The approaches were largely dictated and influenced by the “toolkit” available within each engineering discipline. Generally speaking, every approach draws from a toolkit with a few different parts, like the nuts and bolts that need to be put together, as well as a handful of methods for putting things together, such as the hammers and screwdrivers for assembling the parts. The toolkit also contains concepts and ideas that guide each field. The specific elements of a toolkit tend to vary quite a bit across different disciplines. For example, the mechanical engineer’s toolkit contains materials with a variety of properties, such as metal, plastic, and concrete, as well as tools and methods to manipulate the materials, including saws and welders. Gravity is one example of a concept that they use in their designs. Electrical engineers, on the other hand, have a completely different toolkit. Their parts include wires, resistors, capacitors, and circuit boards, and they have developed their own highly specialized manufacturing processes to create and combine these parts. Electrical engineering ideas further utilize a modern understanding of electrical signals.
For synthetic biology to become a mature engineering discipline, synthetic biologists must define their toolkit. Like mechanical engineering and electrical engineering, the tools will include parts that need to be put together and the methods for assembling them; of course, the parts and methods will be specific to biology. Many of the tools in the synthetic biology toolkit are derived from molecular biology. In the next section, we will introduce some of the components of these previously existing toolkits and explore how they are also implemented in the toolkit of synthetic biology.
The Synthetic Biology Toolkit
To explore the synthetic biology toolkit, let’s first think about how biologists might approach the plant watering challenge. Broadly, they would use genetic tools to change the plants themselves. Such an approach could take many different forms. For example, one solution might use a gene discovered in chameleons that is responsible for changing color in response to stress. It’s possible that this gene could be inserted into plants; thus, they then could change their color to alert us when they need water. This approach is analogous to the mechanical engineer’s approach of adding a visual indicator (the pot tipping over) to help the owner remember when the plant needs water.
There could also be a biological solution that is more analogous to the electrical engineering solution, which frees the owner of the plant from the need to provide water at all. What if it were possible to isolate a gene or two from a cactus plant—or, maybe even more whimsically, from a camel—that helps these organisms withstand the very low water supply in their desert habitats? These genes, inserted into a plant, might help them survive with very little water, as well.
Both of these solutions could be approached with today’s molecular biology tools, but these types of small modifications do not meet the synthetic biologist’s goal of larger-scale genomic manipulation that would be required for an application such as growing a house and all its furniture from a seed. Such wholesale genomic design requires a full engineering toolkit. Such a toolkit must begin with, and build upon, contributions from the established fields of molecular biology and genetic engineering.
The Molecular Biology Toolkit
Molecular biologists have spent years developing methods to manipulate DNA in different ways. Following are three of the most crucial and well-established techniques, which are used extensively in synthetic biology:
§ Reading the DNA code
§ Copying existing DNA sequences
§ Inserting specific DNA sequences into existing DNA strands
These techniques have become well established over years of molecular biology research, and researchers continue to develop new technologies that improve the processes. Dr. Frederick Sanger and Dr. Walter Gilbert developed robust DNA sequencing technology in 1977 using chain-termination chemistry that made it possible to accurately determine the pattern of Gs, As, Ts, and Cs in long DNA strands. Routine copying of existing DNA sequences in a laboratory was jump-started in 1983, when Dr. Kary Mullis developed Polymerase Chain Reaction (PCR). PCR is a powerful method that uses a cellular protein for copying DNA and a genetic template provided by the researcher to synthesize large amounts of a specific DNA sequence. Finally, Dr. Paul Berg, Dr. Stanley Cohen, and Dr. Herbert Boyer developed recombinant DNA (rDNA) techniques in the 1970s with which researchers can easily and precisely combine DNA sequences from different sources, including different organisms, based largely on a variety of naturally occurring proteins called restriction enzymes that cut DNA at specific sequences. These methods were inspired by and use the tools of naturally occurring cellular processes. Table 1-1 illustrates these parallels.
|
Tool |
Molecular biology technique |
Natural cellular process |
|
Reading DNA |
Sequencing |
DNA replication |
|
Copying DNA |
PCR |
DNA replication |
|
Inserting DNA |
rDNA with restriction enzymes and ligases |
Defense from infection, DNA recombination and repair |
|
Table 1-1. The molecular biology toolkit and its natural origins |
||
MOLECULAR BIOLOGY
DNA replication is a naturally occurring cellular process that creates new DNA sequences from existing DNA templates, usually to create new genetic material so that the cell can divide. This process varies between different species and can require many proteins to unwind the DNA and initiate replication, but the key requirements are the following:
DNA polymerase
The enzyme that adds nucleotides to the growing chain.
A DNA primer
This is a short chain of already synthesized DNA that binds to the beginning of the sequence to be replicated (DNA polymerase can only add new bases to an existing chain).
Free nucleotide bases
Free A, T, C, and G nucleotides, together referred to as dNTPs, that are available in the cell to be added to the growing chain.
Sanger sequencing is a laboratory technique to determine the sequence of a DNA fragment. Researchers mix the DNA that they want to sequence with a DNA primer, DNA polymerase, and dNTPs to start replication. Also added to the mix is a small amount of modified bases that stop chain elongation once incorporated. These modified bases are also tagged, usually with radioactivity or fluorescence, and each base has a unique tag. The fragments that result from the disrupted replication process can be ordered based on size, and the sequence is read based on the tag on the modified base at the end of each fragment.
PCR is a laboratory technique to create many copies of an existing piece of DNA. This process mimics natural DNA replication. The researcher combines the desired DNA (called the “template”), primers that specify where the replication should begin and end, DNA polymerase, and dNTPs. The mixture is then cycled through different temperatures that facilitate different steps. First, the mixture is raised to a high temperature so that all the DNA bases are unpaired. The temperature is then lowered, allowing the primers to bind to the template DNA. Finally, the temperature is raised slightly to allow the DNA polymerase to work. This process is repeated many times to create many copies of the desired DNA fragment.
Restriction enzymes rare naturally occurring enzymes, which can also be used in the lab, that cut DNA at specific sequences of bases to create ends that are either blunt or “sticky”; that is, a few unpaired bases at the end of double-stranded DNA. When DNA pieces with complementary sticky ends are combined, they associate with each other, resulting in a new sequence, as illustrated in Figure 1-4.
![]()
Figure 1-4. DNA cut with restriction enzymes. The pairs of black and blue bars represent double-stranded DNA, color coded to show where it has been cut with restriction enzymes to leave complementary “sticky ends” (left) or “blunt” ends (right) that can reconnect as shown.
Plasmid is a small, circular piece of DNA most frequently found in bacteria that persists in the cell independent of chromosomal DNA. They are useful in molecular biology for transferring designed genetic systems into cells of interest. When used for this purpose they are frequently called“vectors.”
The Toolkit Expanded for Synthetic Biology
Although these methods have been around for many years and have been used to great effect in research, they are not sufficient for synthetic biology. They might be sufficient to insert a gene from a chameleon into a plant, for example, but they would not enable the reliable reprogramming of a plant to grow into a two-bedroom, two-bathroom house. Consequently, we use the term genetic engineering, not synthetic biology, to refer to the relatively small-scale manipulation of genes in a host organism, perhaps altering at most a handful of genes.
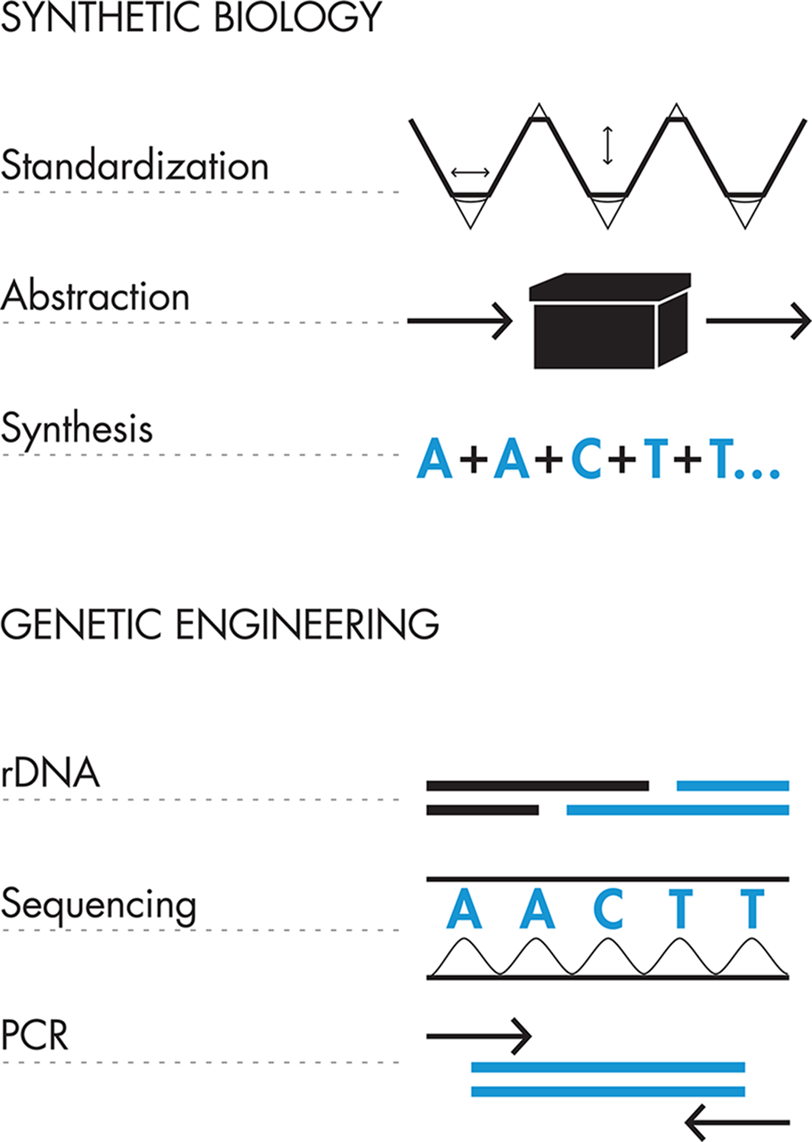
Synthetic biology, on the other hand, aspires to write and rewrite entire genetic programs to create useful functions and products. To achieve these more ambitious engineering goals, synthetic biologists expand their toolkit beyond that of traditional genetic engineering to also include design principles from the more established engineering disciplines. They will frequently draw from the language of engineering, which provides a useful framework for thinking about design.
These additional tools, which are still largely in development, include: standardization, abstraction, and de novo DNA synthesis. Both standardization and abstraction are directly drawn from the toolkits of other engineering disciplines, whereas DNA synthesis is an engineering tool unique to synthetic biology. We will describe each of these topics in more detail later, but following are brief definitions:
DNA synthesis
This is a process for the chemical production of DNA strands without a pre-existing physical template, and is used at a much more extensive level in synthetic biology than is required for molecular biology.
Standardization
This is an approach that aims to generate a set of components that might be useful in multiple systems and that can be recombined for different outcomes.
Abstraction
This is a tool to manage detailed information when building a complex system. With it, designers can “get the job done” without trying to keep in mind exactly how every detail of a system works. In practice, engineers use different levels of abstraction depending on where they are in their design-build-test cycle.
DNA synthesis
DNA can be produced by a series of simple chemical steps that are not fundamentally different from any set of chemical reactions that adds one building block to another. In the case of DNA, these building blocks are nucleotides, but other examples of polymers made from building blocks include proteins made from amino acids and polyethylene made from ethylene monomers. In a cell, DNA is synthesized using large macromolecular complexes that add each subsequent nucleotide to the existing DNA strand. In the lab, chemists have developed alternative methods to produce DNA by chemically appending nucleotides to a growing nucleotide chain.
Whether made in a cell or in a lab, the synthesized DNA must have the correct sequence. In a cell, the DNA sequence is based on an already existing template strand that provides the sequence information. Synthetic biologists, on the other hand, are often designing new sequences for which no template exists. When there is no template strand to follow, they determine the nucleotide order of the synthetic DNA by using digital sequence information. With this technology, synthetic biologists can write new DNA sequences that have never been written before.
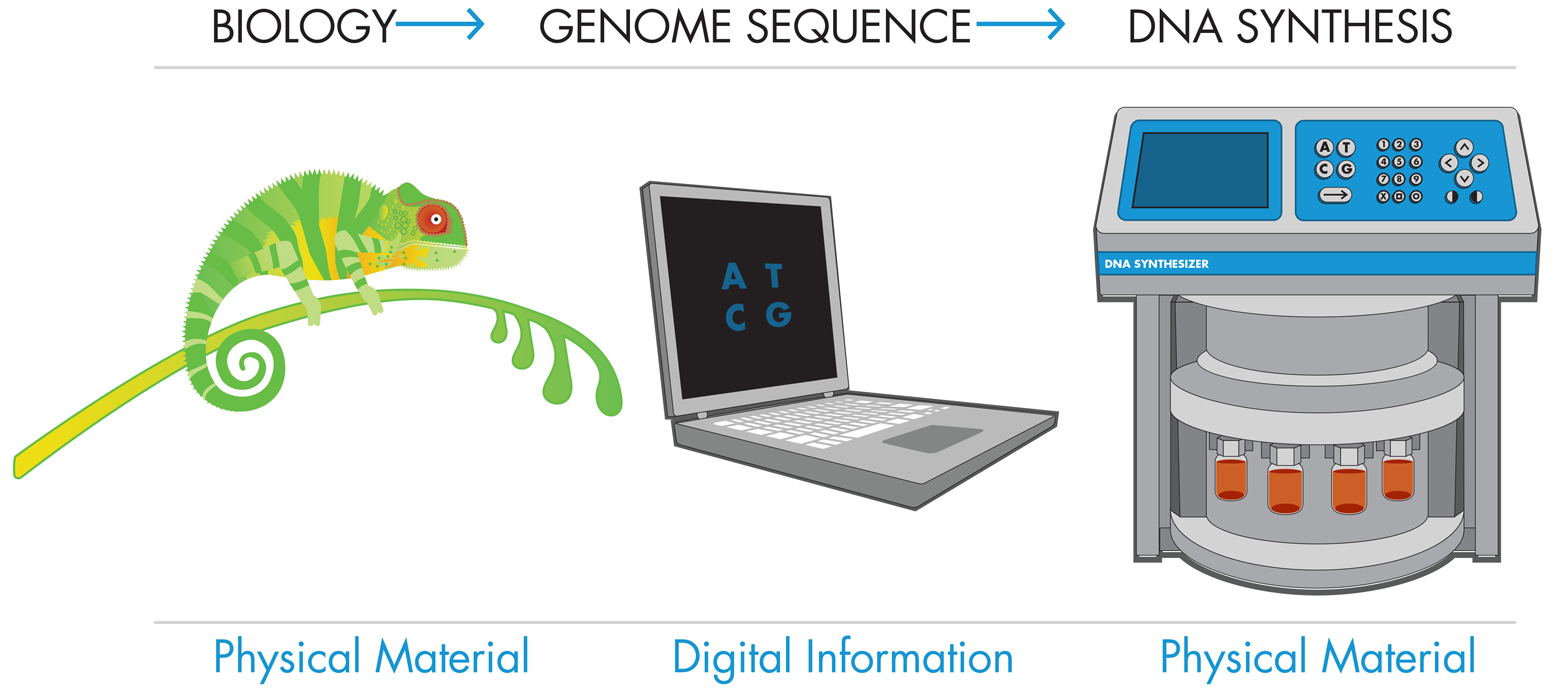
There are some limits to the lengths of the DNA strands that can be produced by this method, but a recent landmark was reached with the synthesis of an entire functional genome by Dr. Craig Venter and colleagues. This achievement simultaneously demonstrated the potential of chemical DNA synthesis as a central component of the synthetic biology toolkit and raised ethical concerns about its use. The researchers rebuilt a genome of the bacterium M. mycoides using chemical synthesis to generate multiple short DNA snippets. They added a few small variations, which they called “watermarks,” to the sequence, and then inserted this synthetic DNA into a microbe (baker’s yeast), where it was assembled into a full genome. Finally, they transplanted the genome into M. capricolum, replacing that bacterium’s existing genomes and essentially converting the M. capricolum shells into M. mycoides. This advance, which sounded to some a lot like Frankenstein’s monster in Mary Shelley’s famous work of fiction, spurred the Presidential Commission for the Study of Bioethical Issues and led to a report, New Directions: The Ethics of Synthetic Biology and Emerging Technologies, which addresses the potential ethical issues associated with synthetic biology and mature DNA synthesis technologies.
Standardization
Standardization is a crucial part of any engineering discipline because it facilitates designers being able to reuse parts, combine efforts with other teams, and work efficiently. For electrical engineering, such standardization means that designers can wire together individual pieces relatively easily so that they can “talk” to one another. For synthetic biologists, standardization enables DNA snippets to be physically and functionally connected.
Physical standards for assembly make it possible for all DNA parts to be attached to other parts through a common strategy. This is similar to the way mechanical engineers can connect any nut to any bolt because these parts all use standard-sized threads. The complexity of the cellular environment and biological systems makes standard composition difficult. Nonetheless, there is an effort to define a standard for DNA assembly so that synthetic biologists have a collection of reliable parts and a place to find standardized genetic elements like promoters or repressors when they want to build with them. Physical standardization of DNA parts is discussed in more detail in the Fundamentals of DNA Engineering chapter.
However, successfully putting pieces together is no guarantee that they’ll work as desired or be interchangeable. An additional consideration isfunctional standardization, meaning that, no matter what the context, a genetic part will reliably encode a particular behavior. One approach in synthetic biology to reach this goal of predictable functionality is the characterization of a cell’s behavior in digital terms: a snippet of DNA is either “on” (that is, expressed by the cell) or “off” (not expressed). This digital principle is familiar from all the electronics in our lives. Our televisions and our cell phones are either on (even if they are “sleeping”) or off. This all-or-none behavior makes it relatively easy to connect different pieces. When the television receives input from the remote control to turn on, it activates and provides video and audio output. The same principle holds for the components that make up electrical circuits: each receives input, either “on” or “off,” which determine its output, also “on” or “off.” This is a highly simplistic description of circuits, but because the “on” and “off” states are standardized across parts, electrical engineers can connect parts and anticipate the behavior of the circuits.
Synthetic biologists are also trying to develop similar “digital standards,” describing a gene or an enzyme as being turned “on” or “off.” Of course, most biological behaviors (such as transcription or enzyme activity) are not completely digital, but the analogy holds well enough as long as we’re careful. Using this approach, we can use other electrical engineering schema, such as wiring diagrams and truth tables, to help us design our systems. These tools are described in more detail in the Fundamentals of Biodesign chapter.
IGEM
The International Genetically Engineered Machines (iGEM) competition applies the concepts of standardization to DNA parts. This competition brings together college and high school students from around the world to answer the question, “Can simple biological systems be built from standard, interchangeable parts and operate in living cells?” The first competition, held in 2004, started with only five schools and a few handfuls of students, but by 2014, the competition hosted 295 teams from 34 countries.
Each iGEM team is challenged to design and construct a novel biological system using the standardized parts in the iGEM Registry of Standard Biological Parts. These parts have standardized junctions, allowing them to be physically connected with a consistent and reusable assembly scheme. Teams can use only four restriction enzymes and the iGEM library of standardized DNA parts to assemble genetic circuits and make more complex arrangements of genetic elements. The reuse of standard biological parts is one way that teams from different schools can share reagents and accelerate everyone’s progress on their summer-long projects. We further explore several iGEM projects, one involving smell and one involving color, in the BioBuilder program.
Abstraction
Through abstraction, synthetic biologists can design complex parts, devices, and systems without worrying about every detail of how they work. Instead, the focus is on the end goal, which is the final system output or behavior. In practice, the design of any new system will use abstraction levels very naturally. At the beginning of the design process, we often will think broadly about possible solutions, worrying very little about the details of their implementation. As the problem and the solutions are broken into smaller parts and become more defined, some of the earlier abstractions become concrete so that we can actually build and test the designed system.
Abstraction is particularly important for synthetic biology because the cellular environment and cellular processes are so complex. If we tried to understand every detail of each new design, we would have to slog through our ideas too slowly. Instead, we can think of a bacterial cell as a “black box” (see Figure 1-5). In other words, we don’t need to get bogged down with the details of each and every pathway within that cell, especially when developing initial designs.

Figure 1-5. Viewing a cell as a black box. Synthetic biology is enabled by abstraction, which allows for engineering of a cell without considering all of the details of each and every pathway within that cell.
Figure 1-6 presents the hierarchal levels of abstraction. At the highest abstraction layer is the system, our cellular black box. Within that system we might be interested in developing a device with a specific function such as sensing an environmental chemical and creating a specific output scent in response. When we decide how we want our device to work, we can begin to think about the different parts we will need to create each device; for example, a way to sense the environmental chemical and a way for that response to control the scent output. Finally, at the lowest level of the abstraction hierarchy—and not abstract at all—are the actual genetic sequences we’ll need to have on hand to use as parts. By breaking the design process into these different layers of abstraction, we have divided the problem into bite-sized pieces that can be addressed more effectively. We will go into detail about each of these levels of abstraction and provide concrete examples of how to implement them in the design process in the Fundamentals of Biodesign chapter.
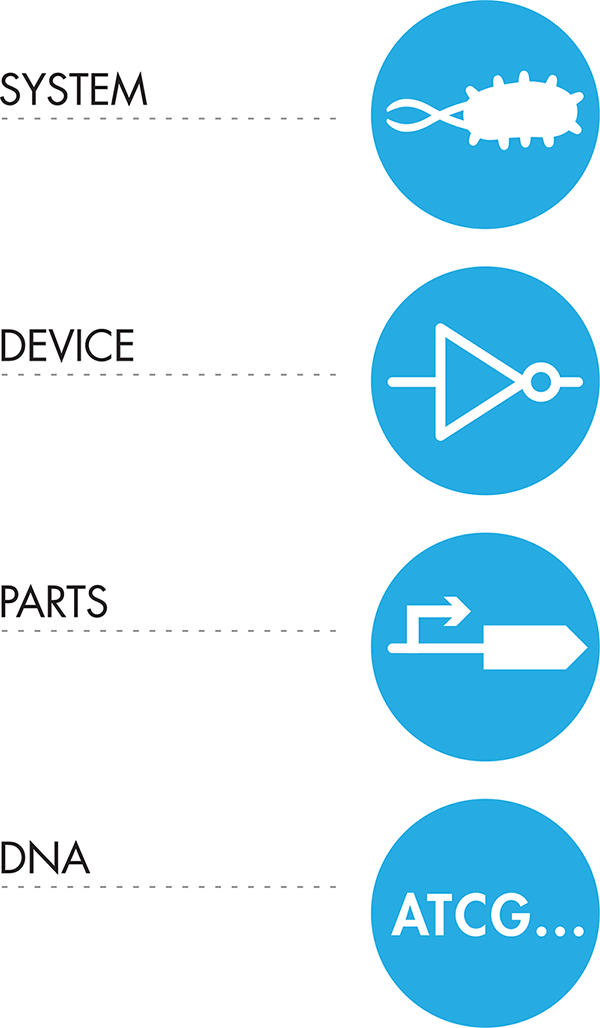
Figure 1-6. Abstraction hierarchy. Abstraction can support complex system design. This abstraction hierarchy is one of many that are possible to use for synthetic biology. The highest level of abstraction here is the entire system, which can then be broken down into specific devices made up of certain parts. The most granular abstraction level here describes the DNA sequences that will be needed to implement the design.
Wrap-Up

In this chapter, we focused on the power of synthetic biology to produce new systems that can provide useful products or services. We have introduced the basic concepts of synthetic biology by explaining how this field differs from traditional biochemistry and molecular biology, and how some of the fundamental principles from established engineering fields inform the way synthetic biologists design and build living biotechnologies.
The engineering and design approach that synthetic biology espouses has broader implications, too. As physicist Richard Feynman said, “What I cannot create, I do not understand.” Though we have certainly come a long way in our understanding of biological systems, we cannot yet build entirely new systems. There is still much to learn about even the most basic biological processes and systems, and synthetic biology provides a powerful new tool in this endeavor, as well.
Additional Reading and Resources
§ Alberts, B. et al. Molecular Biology of the Cell, 4th edition. New York: Garland Science, 2002. Open access: http://bit.ly/mol_bio_of_the_cell.
§ Endy, D. Foundations for Engineering Biology. Nature 2005;438:449-53.
§ Gibson, D. et al. Creation of a Bacterial Cell Controlled by a Chemically Synthesized Genome. Science 2010;329:52-6.
§ Report from the Presidential Commission for the Study of Bioethical Issues (2010) “New Directions: The Ethics of Synthetic Biology and Emerging Technologies” (http://bioethics.gov/synthetic-biology-report).
§ Website: “Fab Tree Hab” design by TerreformOne.org (http://bit.ly/tree_hab).
§ Website: History of rDNA (http://bit.ly/berg_boyer_cohen).
§ Website: iGEM (http://www.igem.org/Main_Page).
§ Website: 1980 Nobel Prize in Chemistry (http://bit.ly/chem_nobel_1980).