An Introduction to Applied Cognitive Psychology - David Groome, Anthony Esgate, Michael W. Eysenck (2016)
Chapter 4. Auditory perception
Kevin Baker
4.1 INTRODUCTION
In this chapter, the nature of auditory perception is considered. First, the nature of sound and the human auditory system are described before comparisons are made with visual perception. A historic account of the development of the study of auditory perception is then presented, including the psychophysical, Gestalt, ecological and auditory scene analysis approaches. This is followed by an account of recent research, including sound localisation, the perception of speech and non-speech sounds, attention and distraction, and the interaction between auditory and other sensory modalities. Applications of auditory perception research are then described, including the use of sound in computer interface design, sonification of data, design of auditory warnings, speech recognition, and forensic applications, including earwitness testimony.
4.2 SOUND, HEARING AND AUDITORY PERCEPTION
WHAT IS SOUND?
Sound is caused by vibrations of air molecules, which in turn are caused by an event involving movement of one or more objects. The pattern of air vibrations is determined by the materials and actions involved in the event. Dense objects, such as stone, make different vibrations from less dense materials, such as wood, and slow scraping movements make different patterns of vibrations from those caused by impacts. Our ears and brains have evolved to pick up these air vibrations and to interpret them as sounds-caused-by-events-at-a-location.
The air vibrations that hit our ears can vary in many ways, but always in the two dimensions of intensity and time. The pattern of vibration may therefore be represented as a waveform of a line on a graph of intensity against time. Intensity here refers to the amount of energy transmitted by the wave, where this is evident as the pressure (sound pressure level) exerted by the sound wave as it travels through the air. High peaks in the waveform indicate high levels of intensity, which we experience as loud sound. A greater number of peaks or troughs per second is referred to as higher frequency and this we experience as a higher pitch. Intensity and frequency are thus physical attributes that can be measured, while loudness and pitch are psychological attributes that result from the perceptual processing by the ears, the auditory nerve and the brain. Since we are capable of registering a very wide range of intensities, the decibel scale used to measure loudness is based on a logarithmic function of the sound pressure level rather than absolute pressure levels.
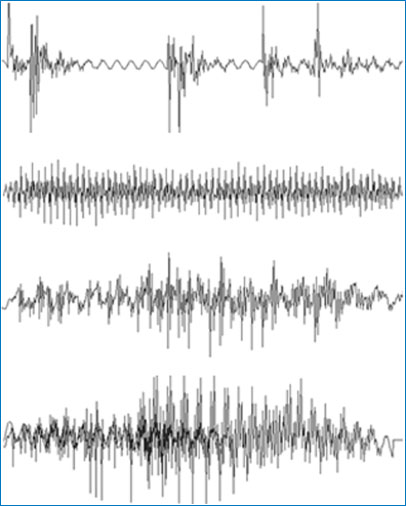
Figure 4.1 (From top to bottom) The waveforms of a pencil falling on to a table top, a mouth-organ playing the note of A, the author saying ‘hello’ and the author saying ‘hello’ at the same time as a woman saying ‘goodbye’.
Figure 4.1 shows the waveforms of a pencil falling onto a wooden surface, a mouth-organ playing an ‘A’ note, the author saying ‘hello’ and the author saying ‘hello’ while his wife is simultaneously saying ‘goodbye’ (in a higher pitch). Although these may be considered to be stimuli which are easily distinguished from each other when we hear them, comparing the waveforms visually suggests that some complex processing is going on.
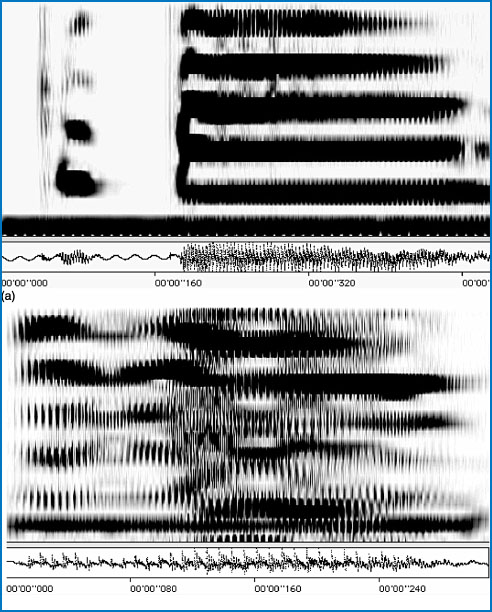
Figure 4.2 Spectrograms of (a) the author saying ‘hello’ and (b) the author saying ‘hello’ at the same time as a woman saying ‘goodbye’.
There is an alternative way of representing sound that gives more information than the waveforms shown in Figure 4.1. The sound spectrogram enables us to display sounds using the three dimensions of frequency, time and intensity. Figure 4.2 shows spectrograms of the same two speech samples recorded for Figure 4.1. The vertical axis displays frequency information, with higher frequencies represented higher up the scale. The horizontal axis is time and the shading of the marks represents intensity, with darker patches having more energy than lighter ones.
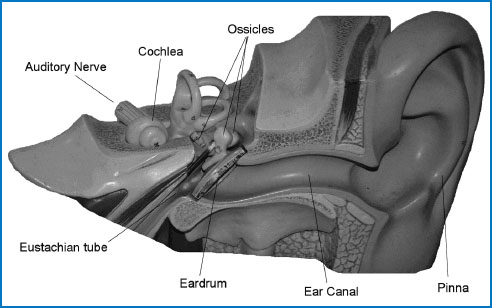
Figure 4.3 The workings of the ear. The external ear consists of the pinna and the ear canal. The middle ear consists of the eardrum (also known as the tympanum) and the ossicles (ear bones). The inner ear is made up of the cochlea and the auditory nerve. The cochlea is a coiled tube-like structure filled with fluid and an array of sensitive hair cells attached to a vibration-sensitive membrane. The balance system, or vestibular system, is also part of the cochlea and consists of three circular tubes filled with fluid and hair cells which transduce the movements of the head into nerve impulses.
WHAT IS THE AUDITORY SYSTEM?
The auditory system operates in three phases: reception, transduction and perception. Sound energy first hits the eardrums and sets them vibrating. These induced vibrations enable the sound energy to be transmitted to the inner ear behind the eardrum (see Figure 4.3), where it is transduced into neural impulses through the cochlea and auditory nerve. Finally, these neural impulses travel to the auditory processing centres in the brain and are interpreted into sound perceptions such as ‘a pencil falling onto a table’ or ‘a mouth-organ playing A’ etc. In effect, the ear analyses the acoustic waveform into frequency and intensity information which is processed and interpreted by the brain.
One could say that hearing begins when one feels the air vibrations on the thin membranes of the eardrums. On the inner side of each eardrum is a chain of three of the smallest bones in the body, called the ossicles. These are vibrated by the eardrum membrane, transforming the air vibrations into mechanical vibrations. We have other mechanoreceptors that are part of other perceptual systems - for example in our skin - that are capable of detecting and transducing mechanical vibration. Some creatures, such as spiders, use mechanical vibration as their main sensory input and so may, in a literal sense, be said to hear (or even see) with their feet.
The last of the ossicles vibrates onto a small membrane covering the end of a fluid-filled coiled canal called the cochlea. Inside the cochlea the vibrations are further transformed into electrical impulses by a highly efficient and sensitive structure of membranes and hair cells. These hair cells, like all hair cells, have receptor nerve-endings which fire an electrical impulse when the hairs are moved. At one end of the cochlea the nerve-endings fire in time with the incoming high-frequency vibrations, while at the other end the nerve-endings pick up the lower frequencies. In this way, the vibrations are transformed into neural firings representing the frequency-intensity changes over time. However, since we can perceive a far greater range of sound frequencies than the membranes of the cochlea can vibrate in sympathy with, complex combinations of inputs from regions of the cochlea are required to transduce those extra frequencies. This is called the ‘volley principle’. Outputs from the receptors are transmitted along nerve fibres that become gathered as nerve bundles. These are then rolled into the auditory nerve. The electrical impulses travel along this nerve through to the mid-brain and on to several sub-cortical structures before finally synapsing on to areas of the cortex where higher-level interpretation is carried out.
At this point, we must be cautious of describing auditory perception as solely a bottom-up process. There are feedback loops that influence our perceptions. For example, when some sounds increase in loudness the hair cells in the cochlea become stiffer to adjust to the increased energy being received. There are also top-down influences at the perceptual and cognitive levels of processing, especially when speech is involved. As in visual perception, the effect of context can also be important in influencing the perception of the sound. These influences indicate that perception has evolved to be an integral part of cognition. For example, when you are aware of hearing a sound, you usually have little trouble recognising what made the sound, which direction it came from, how far away it is, and also any meaning that might reasonably be attached to it. Each of these aspects of hearing can involve the influence of attention, learning and memory along with other cognitive processes. If the sounds are speech sounds, then language processes are heavily involved to help you make sense of the acoustic energy. The same is true of music, which, like language, is another example of structured symbolic processing of sound. The perception of sound ultimately involves cognitive processing and this implies that we need to adopt a cognitive approach in which sensorinformation processing happens along with symbolic information processing to produce a perception.
SEEING AND HEARING
There are several similarities between auditory and visual perception. One is the problem of perceptual constancy. Both perceptual systems manage to deal with widely varying sensory information and give us remarkably stable perceptions. For example, when you see a person walking towards you, you don’t think that the person is growing in size because the retinal image is getting bigger. The perception is constant despite the changing sensory information. Similar constancies are found in auditory perception. This processing is remarkable when you consider that every time a sound is produced it is usually mixed with other sounds from the environment to produce a complex waveform. Separating out sound into perceptual ‘figure and ground’, first described by the Gestalt psychologists, is as important in auditory perception as it is in visual perception.
Like the visual system, the auditory system also has identifiable ‘what’ and ‘where’ pathways (see Groome et al., 2014), which process the location of a sound in parallel to recognising its meaning. For the visual system, recognising an object automatically implies working out where it is, while for audition it is possible to recognise a sound without being aware of its precise location. For humans at least, the auditory system may function in the service of the visual system when we need to locate something. The visual system often takes priority when we need to work out where something is, with hearing only providing supplementary information (Kubovy and van Valkenburg, 2001).
Perhaps due to the primacy of vision, research in perception has tended to be ‘visuo-centric’. The subject matter for visual research is often fairly straightforward to define and control. With hearing it is often difficult to carefully design a stimulus and pass it about so we can experience it under controlled conditions. Visual stimuli can be made invariant over time. We can draw pictures to use in simple experiments and visual illusions can be presented on paper fairly easily. However, sounds are always variant over time. As a result, auditory researchers have had to wait longer for technology to become available that will allow for the construction and control of stimuli for experiments. It is only within the past 50 years that accurate audio recordings have been of high enough quality for this purpose, and only within the past 20 years has technology been widely available for the digital synthesis, recording and editing of sound.
4.3 APPROACHES TO STUDYING AUDITORY PERCEPTION
PSYCHOPHYSICS
Early research into auditory perception was carried out by scientists such as Georg Ohm (1789-1854) and Herman von Helmholtz (1821-1894). They tried to identify the limits of perception in well-controlled laboratory environments. Examples of the types of question they were interested in were: What is the quietest sound one can hear? What is the smallest difference in intensity or pitch that one can detect between two tones? The experimental approach was reductionist in character, with an underlying assumption that in order to understand how we perceive complex sounds, one should begin with ‘simple’ sounds. Thus, sine-wave or ‘pure’ tones were most often used as stimuli.
Psychophysicists thought about the ear as an analytical instrument. They presumed that it split complex sounds into simple components that were then sent to the brain to be reassembled. Hence, if all the data on how we deal with pure tones could be collected, we might uncover the rules governing how our auditory system deals with more complex sounds. In the past 150 years or so, much has been learnt about the physics of sound transmission both inside and outside our ears, but this work is by no means complete.
There have been some excellent practical applications of this approach to research, such as hearing aids, recording techniques and the acoustic design of concert halls and theatres. But there have been many limitations. Hearing aids initially amplified all sound to the same level and were not useful in noisy or busy environments. Modern hearing aid research now applies techniques from artificial intelligence, rather than from human auditory perception, to pre-process sounds before amplifying them.
The limitations of the psychophysicists’ approach are also apparent in a number of simple laboratory observations. Harmonics are multiples of a frequency, and occur in all naturally produced sounds. For example, if you strike the middle A key on a piano, the spectrum of the note would have a fundamental frequency of 440 Hz (i.e. the lowest frequency) and also harmonics of 880 Hz, 1320 Hz and so on (see Figure 4.4). A pure tone consists only of the fundamental frequency; however, some listeners will say that they can hear harmonics from a pure tone, even when presented through headphones. It is possible to synthesise a series of harmonics with a ‘missing’ fundamental (see Figure 4.4) for which people say that they can hear the fundamental frequency, when in theory, they should not be able to (Warren, 1982).
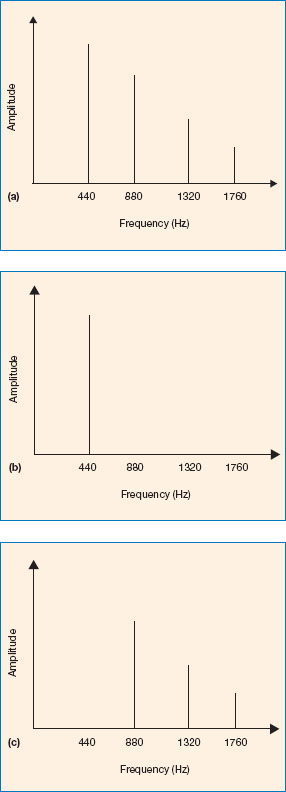
Figure 4.4 Diagrammatic spectrum of a mouth-organ playing the note of middle A. The figure shows the most intense frequencies. (a) A fundamental frequency of 440 Hz and its harmonics. Other frequencies will be present but at much lower intensities. (b) The spectrum of a pure tone at 440 Hz which has no intense harmonics. (c) A synthesised tone made up of the harmonics with a missing fundamental. The missing fundamental does not occur in nature, but our auditory system perceives it as a rich 440 Hz tone nevertheless. In effect, we infer the fundamental frequency.
The observation that the auditory system does not work by deconstructing and then reconstructing sounds should not come as too much of a surprise. The same is true for visual perception. Gunnar Johansson put it eloquently: ‘what is simple for the visual system is complex for our mathematics and what is mathematically simple is hard to deal with for the visual system’ (cited by Jenkins, 1985, p. 102). The physical description of a pure tone is that it is a simple sound. But in perceptual terms this is not necessarily true and the auditory system has not evolved to hear sounds that do not appear in the environment.
GESTALT PSYCHOLOGY
The Gestalt psychologists reacted against the reductionism of psycho-physics and concentrated instead on how we perceive parts of a pattern within the context of a whole. Although much of their focus was explicitly about visual patterns (see Groome et al., 2014), virtually all of their principles are applicable to sound and hearing, such as figure-ground separation mentioned earlier.
The Gestalt principle of ‘continuation’ has often been researched in auditory perception. The tones represented in sound A of Figure 4.5 will be heard as: two beeps of the same pitch separated by a short period of silence. Nothing surprising there! However, when the same beeps are separated by a broad frequency pattern that sounds like a ‘buzz’ or ‘hiss’, as in sound B, two perceptions are possible: either a ‘beep-buzz-beep’, or a ‘beep continuing through a buzz’.
For most people, sound B is usually heard as a beep continuing through a buzz. Why does this happen? A Gestalt psychologist would argue that the auditory system ‘expects’ the beep to continue because of the principle of continuation, and so our perceptual system constructs this perception from that expectation. There is neurological evidence that the auditory cortex makes predictions about sequences of sounds. Bendixen et al. (2009) found that neural responses to predictable but omitted sounds look very similar to the neural responses to a tone when it is actually present.
However, as with their work in visual perception, Gestalt psychologists offer more description than explanation. Many researchers have found that defining how the principles work in applied settings is no easy matter.
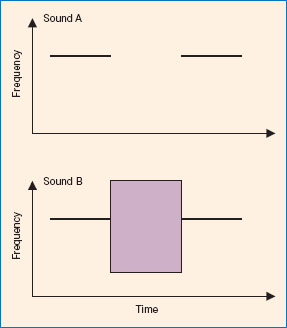
Figure 4.5 Diagrams of two sounds. Two pure tones of the same frequency are represented in sound A. Sound B is made up of the same two pure tones with the gap of silence replaced by a band of noise.
GIBSON’S ECOLOGICAL APPROACH
Like the Gestalt psychologists, Gibson’s (1966) work was mostly focused on visual perception. His initial research grew out of the work he did during the Second World War, defining the visual cues that fighter pilots used to land their planes. Gibson observed that pilots made judgements based on information from all of their senses and argued that this extends to all organisms with perceptual systems. In attempting to address applied problems of perception, Gibson helped move our understanding on.
In many ways, the most attractive feature of Gibson’s approach is this suggestion that there are certain invariant properties in the environment that perceptual systems may take advantage of. The invariant properties of any stimulus will be available even though other properties will be changing and can help maintain the perceptual constancy of an object. This would explain, for example, how we are able to recognise a friend’s voice when their voice is distorted by the telephone or when they have a cold, or are whispering. Despite the acoustic variations in each of these examples, we are still able to recognise some other features of our friend’s voice, perceive this information correctly and understand what they are saying (at least most of the time!).
Shephard (1981) explained this further by arguing that the perceptual system should be able to detect ‘psychophysical complementarity’. He reasoned that because we have evolved in a world that contains regularities, our perceptual systems must have evolved ways of taking advantage of those regularities. In particular, regularities may only be evident when the individual or source of sound is in motion, something that ecologically may be considered a normal state of affairs. Consequently, the ecological approach advocates that experiments should be devised that will tell us whether the perceptual systems really do make use of invariant features. The ecological approach has been very influential in shaping some basic auditory perception research and has drawn together the previously opposed approaches of Gestalt psychology and psychophysics. Like the Gestalt approach, it emphasises the holistic nature of pattern perception but at the same time argues for the need to closely define and measure stimuli and their effects.
AUDITORY SCENE ANALYSIS
Bregman (1990) described the central task faced by research into auditory perception as finding out how parts of the acoustic wave are assigned to perceptual objects and events. He has taken an ecological position by asserting that this has to be done in the context of the ‘normal acoustic environment’, where there is usually more than one sound happening at a time. Our ears receive these sounds as a compound acoustic signal. The auditory system must somehow ‘create individual descriptions that are based on only those components of the sound which have arisen from the same environmental event’ (Bregman, 1993, p. 11). He has coined the term ‘auditory scene analysis’ for this process, after Marr’s approach to visual perception, combining aspects of both Gestalt psychology and ecological psychology.
Bregman’s starting point is to address the separation of sounds into their corresponding auditory events. For example, with the spectrogram in Figure 4.2, which shows the author saying ‘hello’ at the same time are someone else is saying ‘goodbye’, the task of the auditory system is to allocate the different patches of acoustic energy to one perceptual stream representing my voice and to separate it from another stream that corresponds to the other voice. At any one point in time, the auditory system will have to decide which bits of acoustic energy belong together, and this needs to be done simultaneously. The auditory system will also have to decide which bits of acoustic energy should be sequentially grouped together over time. Bregman suggested that this is accomplished through the use of heuristics related to Gestalt grouping principles. A heuristic is a procedure that is likely to lead to the solution of part of a problem, and becomes more successful when used in combination with other heuristics. He proposed that some of these heuristics are innate and some are learnt.
The sounds in Figure 4.5 are usually heard as two perceptual streams of a single long tone continuing through a short noise. These two perceptions can be explained using the Gestalt principle of good continuation along with a heuristic that says ‘it is very rare for one sound to start at exactly the same time that another sound stops’. From this, the auditory system concludes that it is much more likely that the tone is continuing through the noise, and so constructs the perceptions to reflect this. Research into auditory scene analysis aims to uncover and explore the nature of such heuristics employed by the auditory system.
An example of the type of research that explored the grouping principles of continuation and proximity can be seen in the series of experiments carried out by Ciocca and Bregman (1987). They presented varied patterns of tone glides and noise bands to their listeners. Examples of these can be seen in Figure 4.6. All of the glides before and after the noise were varied for their rate of glide and the frequency at which they stopped before the noise band, and started again after it. Note that some of the glides were rising or falling as direct continuations of the previous glide (e.g. A1-B9), and some were near in frequency to the point at which it stopped before the noise band and started after it (e.g. A1-B8). Listeners were asked how clearly they could hear the tone continuing through the noise for each of the different combinations of tone glides. The clearest perceptions were those based on a perception of good continuation - that is, glides A1-B9, A2-B5, and A3-B1. The next-best clear perception was judged to be those based on proximity, either falling and rising glides such as A1-B2, or the rising and falling glide of A3-B8. Ciocca and Bregman’s results clearly show that the listeners heard the glides continuing through the noise band most clearly for only the most ecologically plausible continuations of the tone glides. This is known as a ‘restoration effect’. Such experiments provide strong evidence that the auditory system uses heuristics to integrate sequential acoustic information into streams. It assumes that the auditory scene is being processed as a whole, ahead of the actual perception. For continuation to be possible, the auditory system must to take into account the glide following the noise, and then backtrack in time to complete the perception of a glide continuing through the noise.
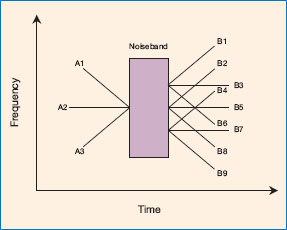
Figure 4.6 A diagrammatic representation of the stimuli used by Ciocca and Bregman (1987). Each presentation consisted of one of three possible tone glides A, followed by a burst of noise and then one of nine possible tone glides B.
Bregman and Pinker (1978) presented the repeated pattern of tones shown in Figure 4.7 to listeners. There are two possible ways in which this pattern could be perceived (shown in the lower panels of the figure): either a fast-beating, high-pitched stream of A + B tones, alternating with a slow-beating, low-pitched tone C; or a single tone A alternating with a complex tone BC. Bregman and Pinker adjusted the frequency of tone A and tone C, and also controlled the timing of tone C relative to tone B, and presented these to their participants. They found that the positions of these tones determined the perceptual organisation of the patterns. If tone A was perceived to be ‘near’ in frequency to tone B, it was integrated into a single stream separate from tone C - a heuristic based on frequency similarity operated on the sequential organisation. How ever, if tone C started and finished at the same time as tone B, a heuristic based on temporal similarity operated on the synchronous organisation that integrated them into the same stream as the complex BC alternating with A. They demonstrated that heuristics act in competition with one another. Thus, tones A and C compete to be grouped with B, influencing a perception which depends on their proximity in time and frequency.
Using heuristics to model human auditory perception means that some kind of metric is needed to judge the frequency and time distances used for grouping. However, when Baker et al. (2000) attempted to use the Bregman and Pinker (1978) experiments to estimate frequency and time distances, they did not appear to be related to a musical scale or any metric used by the cochlea. Clearly more research is needed in this area.
Ellis (1995) has summarised the difficulties in using computers to carry out auditory scene analysis (CASA). He described the ‘hard problems’ faced by software engineers to build computer models of higher auditory functions. Most of these are beyond the scope of this chapter, but the applications are both interesting and challenging. He identified at least three main applications for CASA: a sound-scene describer, a source-separator and a predictive human model. The sound-scene describer would model our ability to convert an acoustic signal into both verbal and symbolic descriptions of the sound source. These could be used by people with hearing impairments to describe an auditory environment using text-based visual displays presenting messages such as ‘there is someone talking behind you’ or ‘there is high wind noise’. It could also be used to automatically index film soundtracks to build databases for searching film and radio archives. The source-separator would be an ‘unmixer’, separating a sound scene into several channels, each coming from a separate source. This would be useful in the restoration of audio recordings to delete unwanted sounds such as a cough at a concert. Additionally, this would assist in the design of hearing aids able to help focus attention in complex auditory environments. Finally, a predictive human model would depend on a very full understanding of auditory perception, but would help in the perfection of hearing aids and the synthesis of sounds for entertainment purposes, such as fully realistic three-dimensional sound.
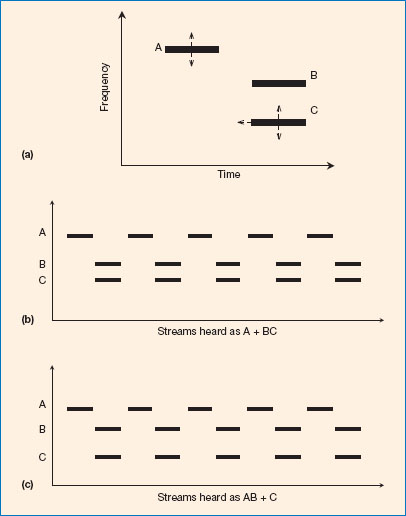
Figure 4.7 A diagrammatic representation of the repeated tonal pattern used by Bregman and Pinker (1978). Each presentation consisted of several successive repetitions of the pattern shown in (a), which was perceived as one of two streams (A + BC, or AB + C) dependent on the proximity of tones A and C to tone B, as represented in (b) and (c).
4.4 AREAS OF RESEARCH
LOCALISATION
There are three sources of information used by the auditory system to localise the origin of a sound: amplitude, time and spectral information. When a sound comes from the left of a person’s head, it hits the left eardrum earlier and with slightly more energy compared with the right eardrum (see Figure 4.8). The distinction between these cues has been known since Lord Raleigh identified them in 1877. This forms the basis of the duplex theory of sound localisation. In general, humans locate sound below 1.5 kHz by analysing temporal differences, while frequencies above 3 kHz are located by the comparing amplitude differences.
Humans are better at locating sounds in the horizontal plane than in the vertical plane (Mills, 1963). When a sound is directly in front of us, above the midline of our heads, or directly behind us, there are no amplitude and time differences between the two ears (see Figure 4.8). In these circumstances, the auditory system uses the changes made to the sound by the shape of the pinnae (i.e. the external ear), and to some extent the shape and reflecting properties of the head and shoulders. The spectrum of the sound will be changed according to its vertical position. Some frequencies are slightly amplified while others are attenuated. Sounds that cover a wide range of frequencies are therefore more easily located than are narrow-band sounds. We can locate sound source with an accuracy of about five degrees (Makous and Middlebrooks, 1990), and this can increase to within two degrees when the sound source is moving and is broadband (like a white noise) rather than a single tone (Harris and Sergeant, 1971). These findings have implications for the design of, for example, telephone rings and emergency vehicle sirens.
Traditionally, most of the research done in this area has used a psychophysical approach. Guski (1990) pointed out that many studies have been carried out under laboratory conditions using artificial sounds in an anechoic room with a participant whose head is in a fixed position and to whom only a restricted range of responses may be available. He pointed out that auditory localisation improves markedly with free head movement (Fisher and Freedman, 1968), the use of natural sound sources (Masterton and Diamond, 1973), and with sound-reflecting walls (Mershon and King, 1975; Mershon et al., 1989). All of these findings emphasised how important it is for research to investigate localisation under ecologically valid conditions. Guski (1990) proposed that because humans evolved with ground-reflecting surfaces throughout most of history, and because side- and ceiling-reflecting surfaces are relatively new phenomena, we should be better at locating sounds with a sound-reflecting surface on the ground than to either the left or right, or above, or one not being present at all. He presented sounds in an anechoic room with a single sound-reflecting aluminium surface placed in different positions (left, right, above and below), and found that localisation was better with the reflecting surface on the floor and worse when it was placed above the listener.
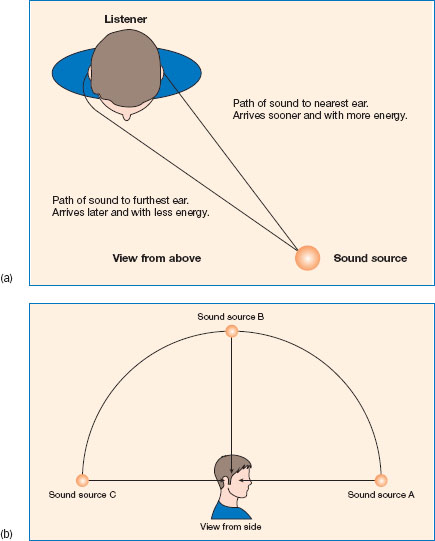
Figure 4.8 (a) In the horizontal plane, time and amplitude differences are used for localisation. (b) In the vertical plane, spectral cues are used. Note that in the vertical plane, time and amplitude differences between the ears will be non-existent.
NON-SPEECH SOUNDS
A purely psychophysical approach to auditory perception can be criticised for not dealing with truly realistic or complex sounds. However, it was only by using pure tones that early researchers showed that the ear does not simply register intensity and frequency changes over time. Originally, it was thought that loudness and pitch were the subjective dimensions of sound that should correlate directly with the physical dimensions of intensity and frequency. However, it was soon realised that our perceptual, or phenomenal, experiences depend on the interaction of several characteristics of the stimulus, as well as the listener’s psychological state and context.
For example, low-frequency tones that have the same intensity as high-frequency tones perceptually sound quieter. Also, tones of around 50 msec duration need to have about twice as much energy to sound as loud as tones of 100 msec. Timbre also appears to be a multidimensional property. Timbre can be defined as the ‘colour’ of a sound. For example, a Spanish guitar has a different timbre from a mouth-organ. Traditionally it was thought that timbre was a property of the harmonic properties of a sound and was an independent perceptual quality in much the same way as pitch and loudness once were. So, for a Spanish guitar and a mouth-organ playing an A note, the harmonics would have the same frequency values, but the relative amplitudes of the harmonics would be different (see Figure 4.9). However, for the perception of timbre, both the attack and decay of the notes are just as important as the frequency spectrum (Handel, 1989).
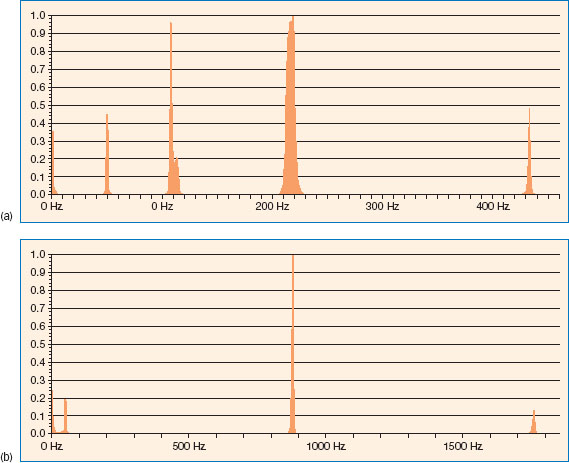
Figure 4.9 (a) The spectra of a Spanish guitar playing the note of A with a strong harmonic at 220 Hz, and (b) the spectra of a mouth-organ playing the note of A with a strong harmonic at 880 Hz. Both sounds are perceived as the same musical note as they are harmonically related by simple ratios of their spectra.
Van Derveer (1979) recorded naturally occurring sounds such as people walking up and down stairs, crumpling paper bags, whistling, jangling keys and hammering nails. She found that listeners were able to identify each sound with a high degree of accuracy. She then asked her participants to group similar sounds together in any way they thought appropriate. So, for example, the sounds of the keys jingling and jingling coins were grouped together, as were shuffling cards, crumpling bags, and crumpling and tearing up paper. Van Derveer found that listeners tend to classify sounds according to the gross temporal patterning, or rhythm, as well as on the basis of the continuity of the sounds. So the jingling keys and coins were judged as similar because of the irregular metallic sounds they produced. The cards and paper were grouped together because of the crackling sound that was continuous through the events. Other researchers have supported the conjecture that it is the temporal structure of sound that is important for the perception of non-speech sounds (e.g. Warren and Verbrugge, 1984).
There is further evidence that we use top-down processing to make sense of sounds. Repp (1987) made recordings of people clapping their hands and reduced this down to a subset of the spectral features. The types of clap were represented by the spectral features and were visually identifiable on a spectrogram. Two cupped hands looked and sounded different from two flat hands clapping. The listeners could distinguish the claps but could not identify the clapper other than themselves. Interestingly, they often made judgements about the gender of the clapper, even though these were guesses no more significant than chance. In a study asking listeners to make judgements about the sounds of people walking, Li et al. (1991) found that people could correctly identify the gender of the walker. However, when they asked men and women to walk in gender-appropriate and inappropriate shoes, the level of identification reduced to chance. It seems that rather than base their judgements on the gait of a person’s walk, listeners used expectations about shoe-types to judge the gender of the walker. Ballas and Howard (1987) suggested that we continually attempt to construct meanings for the sounds we hear and drew parallels with some of the processes found in speech perception.
SPEECH PERCEPTION
Whereas non-speech sounds indicate to us that something has moved somewhere in the environment, when we listen to speech we do not notice the actual sounds being made, but instead process the meaning effortlessly if we are fluent in that language. A major problem in speech perception research is defining what is being processed from the acoustic signal. When the first sound spectrograms were available, there was some optimism that once we could objectively represent and measure the complex speech waveform, it would be a simple matter of finding the invariants for each speech sound. However, the way we process speech is much more complex.
One of the first findings in speech research was that there seemed to be very few gaps between spoken words in normal speech. In fact, it is often possible to locate lengths of silence in the middle of words that are longer than those between words. The gaps between words are perceptual illusions. This is often apparent when you listen to speech in a foreign language and struggle to hear any gaps between words. Solving this problem is one focus for speech perception research.
There are further problems at the level of each speech sound. A word like CAT is made up of the three sounds, or phonemes, [k], [a] and [t], and a word like SHED is made up of three phonemes [sh], [e] and [d]. Phonemes are usually defined according to the way in which their sounds are produced by the position and movements of the tongue, lips, jaws and vocal cords. However, the spectrograms for a Londoner and a Glaswegian saying the same word may be dramatically different. Likewise the speech of children, women and men differ in pitch due to the difference between the length of their vocal cords, with deeper or lower voices being produced by longer and more slowly vibrating vocal cords.
Not only is there variation between speakers, there is also often variation in the same phoneme from the same speaker. For example, the acoustic signal for the [k] in CAT is not the same as the [k] in SCHOOL or NECK. If you were to record someone saying each of these words, you could not simply splice the [k] sounds, swap them around and hear the original words unchanged. The speech sounds preceding and following each [k] phoneme influence how the sound is produced and its acoustic structure. Even isolating each [k] sound is not a straightforward task, because some of its perceptual information is linked to its preceding speech sounds and also overlaps any following phoneme. This phenomenon is referred to as co-articulation (Liberman, 1970).
The incredible complexity involved in the speech signal is remarkable given that we hear and understand speech so quickly - at up to 10 phonemes a second in some cases (Liberman et al., 1967). Because of this, some researchers have suggested that speech is processed by a dedicated and specialised processing system. This is supported by research into categorical perception. Categorical perception refers to the way in which some sounds are perceived categorically regardless of any variation of some of the parameters. A lot of the research in this area has used the syllables [ba] and [pa]. These sounds are produced in the same way apart from the timing of the vibration of the vocal cords. Both phonemes begin with closed lips being opened and the release of air from the mouth outwards. Phoneticians call this a bilabial plosive. The [b] is differentiated from the [p] only by the timing of the vocal cords vibrating after the opening of the lips (see Figure 4.10). The timing is called the voice onset time (VOT). It is possible to manipulate the length of the VOT and run controlled experiments using synthetic speech.
Lisker and Abramson (1970) asked listeners to identify and name synthetic phonemes and found that there was very little overlap in their perception. The participants very rarely got confused or said that the sound was somewhere between a [b] and a [p]. This suggested that the phonemes were perceived categorically. In addition, when the VOT is varied within the normal range of a phoneme, listeners are very poor at distinguishing them. For example, a [b] that has a VOT of 10 msec is not perceived as being different from one with a VOT of 20 msec. When the VOT varies across the normal range, discrimination is easier: for example, a VOT of 20 msec is perceived as a [b] and a VOT of 30 msec is perceived as a [p].
However, the conclusion that we process speech differently from non-speech sounds is an over-simplification because categorical perception has also been found for non-speech sounds (see Cutting and Rosner, 1976; Pisoni and Luce, 1986) and sign language (Emmorey et al., 2003), and even some animals do it. It would appear that we are able to process even complex sounds very efficiently and we may use categories to do this even with non-speech sounds.
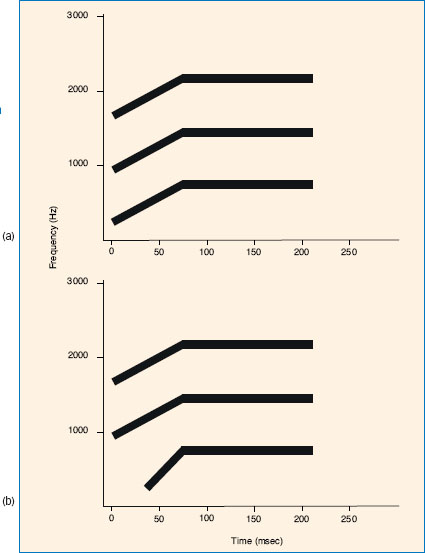
Figure 4.10 Diagrammatic spectrographs of artificial [ba] and [pa] phonemes synthesised with three formants. The diagrams show the onset of the voicing in the fundamental frequency. In (a) the voicing of the fundamental frequency occurs at 0 msec latency, and is perceived as a ‘ba’ speech sound. In (b) the voicing occurs 35 msec after the beginning of speech and is perceived as a ‘pa’ speech sound.
Categorical perception suggests that we have evolved more efficient ways of processing sounds by ignoring some information in the acoustic signal and use the influence of top-down processing to help us to become even more efficient. Warren (1970) presented the sentence ‘The state governors met with their respective legislatures convening in the capital city’ to listeners and replaced the middle ‘s’ in ‘legislatures’ with a 120 msec tone. Only 5 per cent of listeners reported hearing the tone, but despite hearing it they could not identify where in the sentence they had heard it. This phonemic restoration effect is quite reliable.
In a second study, Warren and Warren (1970) presented listeners with variations of the same sentence with the same phoneme replaced by a noise burst:
It was found that the -eel was on the axle.
It was found that the -eel was on the shoe.
It was found that the -eel was on the orange.
It was found that the -eel was on the table.
The participants reported hearing the words wheel, heel, peel and meal in each sentence, respectively. Remarkably, the perception of the missing phoneme in ‘-eel’ was dependent on the perception of the final word. Evidently, speech perception can involve backward processing of the phonemes. Once again, the auditory system processes the acoustic signal, waits for any further information that may be useful for inclusion, and then backtracks in time to influence the perception. This phonemic restoration effect, however, is at a higher level of cognitive and linguistic processing than is evident in the restoration effect shown by Ciocca and Bregman (1987).
4.5 APPLICATIONS OF AUDITORY PERCEPTION RESEARCH
THE APPLIED USE OF SOUND
So far we have seen that our understanding of auditory perception has progressed through the tensions produced by two traditions of scientific investigation. On the one hand, an experimental approach seeks to define and control the sounds presented to listeners and explore their perceptions through their responses, while on the other, our understanding of how we perceive sound in the environment encourages us to investigate what processes are involved in creating the perceptions. When sound is used in applied settings, findings from both traditions can often inform the solutions to problems and also produce the impetus for focusing our research to increase our understanding.
Sounds have been used in creative ways to add dramatic effects to films and animation for many years. Romantic moments are often accompanied by soothing violin melodies, and suspense is often increased with the use of staccato. In science fiction films and computer games, sound effects add to the drama by playing with our imaginations. How to use sound effectively has raised questions for scientists and engineers in a variety of applied fields who seek solutions for some of the problems they come across. In the following sections some of these problems and areas of application are described.
AUDITORY INTERFACES AND DISPLAYS
A systematically researched application is computer interface design. Over the past two decades, using sound in interface designs has developed from the observation that sound is an information-carrying medium. It is especially useful in alerting us that something is happening outside our field of vision or attention. Sound is also used to convey meaning, such as feedback about actions. Gaver (1986) argued that sound feedback is essential to tell us what is happening when the event is not visible or when the eyes are busy elsewhere. We know that providing more information to a person can improve their ability to cope with the environment. For example, giving people headsets with auditory information significantly improves how they navigate a complex virtual environment in both experiments and computer games (Grohn et al., 2005).
There are two main types of sound-design used in interfaces: auditory icons and earcons. Auditory icons are caricatures of everyday sounds, where the source of the sound is designed to correspond to an event in the interface (Brazil and Fernström, 2011). For example, opening a folder may be accompanied by the sound of a filing cabinet drawer opening, or putting a file in the trash or re-cycle bin is accompanied by a scrunching-up sound. Auditory icons reflect the user’s knowledge of the real world and how it works. Earcons are based on musical motifs such as a short melody, and they are designed to represent aspects of the interface (McGookin and Brewster, 2011). For example, when a folder is opened a musical crescendo might be played, and when it is closed a descending sequence of notes is played. Researchers have carried out studies to determine which type of sounds users prefer, usually with mixed results. For example, Jones and Furner (1989) found that users preferred an earcon to denote interface commands such as delete or copy, but when asked to associate a sound with a command, auditory icons proved to be more popular, probably because of the inherent semantic meaning available in such a sound. Lucas (1994) found no difference in error rates for learning the association between commands and auditory icons and earcons.
Bussemakers and de Haan (2000) found that when auditory icons are linked with congruent or incongruent visuals (e.g. a picture of a dog with a sound of a dog, or a picture of a dog with a sound of a duck), response times to decide about congruence or incongruence were faster than when the pictures were presented with either earcons or silence. Moreover, it appears to be the case that earcons are difficult to design and are frequently ineffective or simply irritating (Brewster et al., 1992). Current research is still exploring good design principles for the use of both auditory icons and earcons. With the careful design of musically distinct earcons listeners are able to accurately recall as many as twenty-five sounds regardless of their musical ability (Leplâtre and Brewster, 1998). Leplâtre and Brewster (2000) asked users to complete a set of navigational tasks on a mobile phone simulation with and without earcons accompanying the selection of menu items. Those who heard earcons completed the tasks with fewer keystrokes and faster practice, and completed more tasks successfully than those not using earcons. More recently, speeded-up speech recordings, called ‘spearcons’, have been shown to be even easier to understand and apply (Dingler et al., 2008).
SONIFICATION
Synthesised sound can be used to help visualise quite complex data sets by using the data to control the sound output. This has been applied to geographical data used for gas exploration (Barras and Zehner, 2000), planetary seismology (Dombois, 2001) and a wide variety of uses in medicine, such as monitoring during anaesthesia and guidance biopsy needles (Sanderson et al., 2009; Wegner and Karron, 1998). This relatively new technique of data visualisation is called sonification. Neuhoff (2011) reflected that the field originally underestimated the importance of perceptual and cognitive processes because they seem so effortless. He pointed to the large amount of research which indicates that the way we create meaning from acoustic information is influenced by perceptual and cognitive processes involved when we interact, or intend to interact, with the environment. He concludes that understanding our perceptual, cognitive and behavioural abilities and processes is fundamental to designing auditory displays.
This is still a challenge for sound engineers, psychologists and composers alike. First, the data have to be time based, or converted to be time based, as sound exists and changes in time. Then a particular type of sound has to be chosen to represent each data set (e.g. water sounds, crunching sounds, metallic sounds, etc.). Lastly, the parameters of the sound to be controlled by the data have to be decided upon: will it change the pitch, loudness, timbre, vibrato, position in three-dimensional space, or some other attribute of the sound? Each of these may possibly influence or change our perceptions of the original data and needs to be assessed carefully. For example, Neuhoff et al. (2002) mapped price changes in fictitious stock market data to pitch, and changes in numbers of shares traded to loudness, and presented them to listeners under two conditions and asked them to judge the final price of the stock. In the double-rise condition, both the price (pitch) and numbers of stock (loudness) were increased. In the contrast condition, the price rose and the numbers of stock fell. In both conditions the price rose to the same point, but judgements about the final price were lower in the contrast condition.
So, there are some important restrictions in sonification if we know that some of the dimensions of a sound can distort how we perceive and make judgements about the data it is intended to represent. Gaver’s (1993) analysis of the dimensions of natural sounds has been helpful in this respect and can influence how we design sounds to link with cognitive judgements. Scaletti and Craig (1991) have argued that sonification comes into its own with complex data sets in addition to normal visualisation techniques, so that when the eyes are focused on one or two aspects of the data, our ears can listen to other aspects of the data. In addition, our ears are able to detect smaller changes than our eyes, so it is possible to follow two streams of sound, one presented to each ear. Research in this area is still relatively new and interdisciplinary, integrating ideas from perception, acoustics, design, the arts and engineering (Kramer et al., 2010).
NAVIGATIONAL AIDS FOR PEOPLE WITH VISUAL IMPAIRMENTS
Warren (1982) pointed out that quite a number of sightless people are able to avoid colliding with obstacles through the echoes reflected from surfaces, but that they are not aware that they are using hearing to do so. This has been known for some time and several studies report that people describe feeling the pressure ‘waves’ on their faces when approaching objects rather than any change in sounds (e.g. Supa et al., 1944; Worchel and Dallenbach, 1947). Warren suggested that this makes sense when one considers that we are aware of events correlated with perceptual input rather than sensation (1982, p. 191).
You can explore this yourselves when you hear a sound in a small enclosed space (Guski, 1990). The enclosed space will produce echoes but these are not the same as those you hear in a large auditorium or in a deep valley. The echoes in a room are short and are milliseconds in delay after the original sound, whereas the echoes in a deep valley are much longer. You perceive the echoes in the room as information about the room. In a room with thick curtains and carpets, your voice will be heard with a dull or clipped quality, whereas in a room with shiny, reflective floors your voice will appear to have a brighter quality. The acoustic signal of your voice does not actually change, but your auditory system processes the echoes and reflections influencing the quality of the sound you perceive. However, if you listen to a recording of sounds made in an echoic environment such as a cathedral and then play the recording backward, you will be more aware of the echoes being present.
Some engineers have attempted to develop navigational aids for people with visual impairments by drawing on the principles of data sonification. Instead of numerical data being the input for sound synthesis, a representation of a visual scene is used (Walker and Lindsay, 2005). A common arrangement is to have a laser range-finder scan the environment, with its output influencing a sound. This is similar to the reversing sounds found in some vehicles, which increase in tempo or pitch as you reverse closer to an object. Other systems use a camera on a headset worn by the visually impaired person, with a small computer reading the visual scene and converting the image into an image made up of black and white pixels, which is then converted into high and low pitches (e.g. Meijer, 1993). The scene is played through headphones as a time-changing sound pattern played from the left of the image to the right. Initially, the sounds are confusing and do not represent anything useful to the listener. However, with practice, a user will be able to remember the sound signatures of certain scenes, so that, for example, an open doorway sounds different from a closed doorway, and then begin to use the device to help them hear their way around their environment.
Nagarajan et al. (2004) tackled the problem often found with auditory navigation aids, where background objects can interfere and confuse the person’s understanding of the sounds made by the device. They used signal processing in the same way as the visual system by prioritising information about edges and suppressing background information. Edge detection makes nearby objects stand out, while background information is not so important and is suppressed although not deleted. Nagarajan et al. (2004) used stereo sounds to help the visually impaired listener scan the environment to acoustically detect objects in their way. Other systems work very much like vehicle satnav systems, with recorded voice instructions guiding the visually impaired person around a building.
WARNING SOUNDS
There seems to be something very different between hearing and vision when it comes to attention. Hearing is often described as an orienting system, the purpose of which is to alert an animal to changes in the environment and make it aware of the direction of a possible attack or food source. Most predators, such as owls, foxes and cats, have very acute hearing, which is often matched by some, but not all, of their prey. Acoustic alerts often work better than visual ones, as the receptor organs do not need to be focused on the source and, unlike light, sound is both transmitted in the dark and goes around corners. We use artificial warning sounds in a variety of situations in the modern world. Improving the efficiency of such sounds for emergency situations is obviously an important application of our knowledge of complex sounds and how they are perceived. This may apply to improving warnings for machine operators as well as the improvement of distress signals in emergencies when vision is unclear.
Norman (1988) pointed out that in order for warning sounds to be used correctly, they have to be designed to be truly useful or people tend to ignore them. He described the example of the warning buzzer used in some cars to tell you that the door is open when the keys are in the ignition. The buzzer sounds to get your attention in order to prevent you from locking your keys in the car. But what happens when this is ignored, for example when you open the door while the car is running to pay for your ticket at a car park? In this situation, the buzzer may get your attention, but the significance is changed and you don’t act on it. The problem may now arise that the buzzer may not get your attention with as much urgency or meaning as the designer had intended. As an example of bad design in the past, some firefighters used personal locators which emitted a high-pitched tone at around 3 kHz to locate colleagues when vision was impeded by smoke. However, the frequencies were not optimal for localisation, because single tones of around 3 kHz produce some of the highest errors in localisation (Handel, 1989). Using our knowledge of the auditory system’s ability to locate sound, it should be possible to make improvements to such a device to lessen any confusion and make location more accurate.
Ambulance sirens have been improved in such a way. Withington (1999) ran an experimental study using 200 participants to improve the localisation of ambulance sirens (Figure 4.11). The participants were asked to locate the direction of four different sirens while seated in a driving simulator surrounded by eight loudspeakers. These sirens were: a traditional ‘hi-lo’ siren synthesised from a two-tone signal (670-1100 Hz, 55 cycles/min); a ‘pulsar’ siren made from a pulsing sound (500-1800 Hz, 70 cycles/min); a ‘wail’, a continuous rising and falling tone (500-1800 Hz, 11 cycles/min); and a ‘yelp’ siren, a continuous, fast warbling sound (500-1800 Hz, 55 cycles/min). Withington found that many of her participants confused the front-back location of the sirens and made more false localisation judgements than correct ones, a performance level that was worse than chance! She consequently tested a range of new siren signals optimised for alerting and localisation. These were distinctively different from the traditional sirens, having been synthesised from pulses of rapidly rising frequency sweeps followed by bursts of broadband noise. Participants showed an improvement in their front-back localisation from 56 to 82 per cent, together with an improvement in their left-right accuracy from 79 to 97 per cent. Howard et al. (2011) showed that lower-frequency sounds were useful for the siren sounds to penetrate into other vehicles on the road.

Figure 4.11 The sound properties of emergency vehicle alarms and sirens have been studied to optimise how we perceive them. Our perception of which direction a speeding emergency vehicle is coming from and where it is going can be influenced through the types of sounds the sirens produce.
Source: copyright Sue Robinson / Shutterstock.com.
Warning signals are primarily designed to help the listener locate where the sound is coming from, but some consideration may be made to indicate what the sound means. For example, in the design of complex arrays of consoles (such as those in aircraft), it is important to reduce confusion when a siren sounds. This can be done through the use of good design considerations, either by reducing the number of audible alarms or by making them quite distinct from one another. Patterson (1990) suggested that the use of frequency, intensity and rate of presentation should be used to define the different meanings of a warning sound. In addition, other aspects of the signal can be enhanced, such as the directional characteristics and/or the spectral shape and content, and/or synchronising with a visual signal. For example, if two alarm signals happen at similar times, one can be located high and to the left with the other lower and to the right of a control panel; or one could be high in pitch, the other lower in pitch; or, one could vary at the same rate as a fast flashing visual light source, the other with a slowly rotating light source. It is possible to apply findings from streaming research (e.g. Bregman, 1990) and knowledge about the psychophysics of sound perception (e.g. Haas and Edworthy, 1996) to enhance the perceptual segregation and localisation of alarms.
MACHINE SPEECH RECOGNITION
Machine speech recognition has developed quickly over the past two decades. This has been mainly due to the increased availability of cheaper computing power and developments in software engineering rather than any rapid advances in our understanding of speech recognition and perception. What used only to be done in specialist labs in universities with expensive computers can now be done with an affordable smartphone. Now nearly all computers, tablets and mobile phones come with some form of voice technology. Automatic systems are used in call centres to navigate menus and even help identify irate customers who can be directed to a real customer service rep. Product designers are looking for further applications for improved speech recognition, such as televisions, recording devices and cars.
Most speech recognition software consists of two subsystems, an automatic speech recogniser for transcribing the speech sounds into text-based form, and a language-understanding system to improve on the recognition of the intended message. Research covers all levels of investigation into speech, from acoustic-phonetics and pattern recognition to psycholinguistics and neuroscience. Increasingly, many include several engineering solutions to the problems not immediately solved by human research. In the past, virtually all speech recognition software relied on training to recognise a speaker’s pronunciation. Now, with the ability to connect through mobile phone networks and the internet, voice recognition software often happens remotely, with the company collecting millions of examples of speech to improve performance.
There are two major approaches used by speech recognition systems. The acoustic-phonetics approach attempts to recognise the phonemes in the acoustic signal by trying to identify and match features such as formant frequency, and voicing based on perceptual research (Zue, 1985). This can give a depth of information, such as the emotional meaning of the way somebody says something (Ververidis and Kotropoulos, 2006). Other approaches do not rely explicitly on human behaviour but instead either use mathematical models to match patterns in the acoustics signal (e.g. Huang et al., 1990), or employ artificial intelligence (e.g. Mori et al., 1987; Lippmann, 1989).
The accuracy of recognition has improved, with the number of errors made falling to around 6-8 per cent under favourable conditions. In comparing the performance of machine speech recognition with human speech recognition, researchers assert that more research needs to be done on how humans recognise speech at the acoustic-phonetic level in naturalistic situations (Lippmann, 1997; Lotto and Holt, 2010). In an attempt to improve recognition under difficult conditions and also to solve the problem of learning new words, de Sa (1999) argued for the use of a multimodal speech recogniser. She has persuasively suggested that because integrating both visual and auditory information, as illustrated by the McGurk effect (McGurk and MacDonald, 1976), is the norm in human speech recognition, machine recognition would improve by mimicking this. To this end, she has demonstrated a working neural network application that had learnt to distinguish consonant-vowel syllables using both visual information from lip movements and acoustic signals.
FORENSIC APPLICATIONS (EARWITNESS)
Auditory perception research has been used in the courts and justice systems for some time. The main applications have focused on phonetics and the effectiveness of earwitness evidence. Other applications include determining the authenticity of audio recordings, identification of unclear or degraded recorded utterances, and the identification of speakers from audio recordings. There are two main traditions in speaker identification from an audio recording (French, 1994). American studies have usually relied on a mechanical or spectrographic description of a speaker’s utterances, called a ‘voicegram’ or ‘voiceprint’ analysis. Voiceprint analysis has been considered as an identification method for automated cash tills, but retinal scanning and iris-identification are less variable and hence more reliable. In Britain, contested evidence has been traditionally analysed by a trained phonetician using their skill and knowledge of speech sounds and language to match identification.
Earwitnesses have been an important source of evidence since the famous Lindbergh case in 1935, which involved the recognition of a kidnapper’s voice saying ‘Hey Doc - over here’. Bruno Hauptman was convicted and sentenced to death on the strength of earwitness testimony recalling the events 33 months after the incident. At the time there was virtually no research available to help the court and the situation does not seem to have changed much in the intervening years, with present-day research being scarce and often unsystematic in comparison with eyewitness research (Wilding et al., 2000). What research there is tells us that we are fairly good at recognising familiar voices, not very good at all with unfamiliar voices, and that for both types of voice we tend to overestimate our ability to identify the speaker correctly (Künzel, 1994; Yarmey, 2013).
In comparison with eyewitnesses in similar situations, earwitnesses are less accurate and are usually overconfident about their judgements (Olsson et al., 1998). In fact, research has shown that the confidence one has about how well one can remember a voice before a lineup is not related to the actual recognition accuracy but is related to post-lineup willingness to testify (Van Wallendael et al., 1994). Obviously witnesses think they are able to recognise voices fairly well, perhaps assuming that their memory is like a tape recording of reality, but are able to reassess this assumption when they are asked to actually put their ability to the test. This is an important distinction to make when one considers the difference between jurors and witnesses. Jurors will infer a higher level of confidence and ability in an earwitness report and may base their decisions on this unrealistic judgement.
McAllister et al. (1988) found that earwitness reports were more vulnerable to misleading post-event information than eyewitness memory for a car accident scenario. They used a version of Loftus and Palmer’s (1974) experiment in which participants were required to estimate the speed of cars involved in a traffic accident. Whispering, voice distinctiveness and the length of the utterance have all been shown to have a negative effect on voice identification (Bull and Clifford, 1984; Orchard and Yarmey, 1995). On the other hand, voice distinctiveness can improve identification so much as to possibly bias the recognition in a lineup, and in such a situation the length of the speech utterance has no effect on the efficacy of recognition (Roebuck and Wilding, 1993), which suggests that witnesses can make a best guess by eliminating mismatching voices rather than accurately identifying the correct one, consequently leading to false-positive identification (Künzel, 1994). However, in situations with less varied and fewer voices, the length of the utterance is important in helping improve identification (Orchard and Yarmey, 1995), presumably in aiding the witness to establish a template for later recognition (Cook and Wilding, 1997a). Repetition of the utterance in the lineup can also help to improve recognition, possibly allowing the listener more opportunity to process the speech in a more careful manner (Wilding et al., 2000; Yarmey, 2013).
It appears that the context of the voice recognition can also be important. Cook and Wilding (1997b) reported that in conditions in which the face of the voice’s owner is present, recognition memory for the voice of a stranger is superior to recognition memory when the face is absent. They termed this phenomenon the ‘face overshadowing effect’. This contrasts with their additional findings that other forms of context (such as another voice, name and personal information) had no effect, and neither did re-presenting the face at lineup. Wilding et al. (2000) have some important things to say about the face overshadowing effect. They point out that voice processing is usually added on to theories of face perception in a separate channel. But their findings that the simultaneous presentation of faces with voices interacts to the detriment of voice recognition runs counter to the expectation that voice is a separate and additional channel of information relevant to face recognition. Presumably, the situation is more complex than at first proposed. Wilding et al. (2000) suggested that we do not use voice recognition to help us identify a person’s identity but rather the content of the message. The speech and voice characteristics are primarily extracted to aid speech perception, which is supported by the common-sense notion that knowing a speaker’s identity will help in speech processing (Nygaard and Pisoni, 1998). Face recognition is primarily visual, whereas speech comprehension is primarily auditory in character. The face overshadowing effect is presented as evidence that identifying a person is primarily a visual task, with auditory processing taking a back seat.
SUMMARY
✵ Information about intensity and frequency is processed in auditory perception to give us a wide range of subjective perceptual qualities.
✵ Perceptual constancy is a problem in auditory perception, as the acoustic signal is both linear and can be an aggregate of many different sounds at the same time.
✵ Psychophysics focuses on measuring the limits of hearing using presumed simple tones, whereas Gestalt psychology concentrates on the ability of the auditory system to process patterns into wholes but is vague as to the mechanisms involved.
✵ Ecological psychology looks for invariants in the acoustic signal, and auditory scene analysis is concerned with how we perceive auditory objects and events in noisy situations via the use of heuristics.
✵ Researchers have to be careful to design ecologically valid experiments when investigating the abilities of the auditory system.
✵ For both non-speech and speech sounds, the temporal patterning of sounds is important. Both seem to be processed forward and backward in time before a percept is formed.
✵ Speech perception involves a high level of top-down processing.
✵ Auditory aspects of unattended sounds are often processed.
✵ Auditory perception interacts with other senses.
✵ Applications of auditory perception research include interface design, sonification, navigational aids, the design of warning sounds, machine speech recognition and earwitness testimony. These are all currently active areas of research and development.
FURTHER READING
✵ Bregman, A.S. (1990). Auditory scene analysis. Boston, MA: MIT Press. A thorough introduction to auditory scene analysis. Written by the most influential research professor in the area. A big read, but exhaustive.
✵ Edworthy, S. and Adams A. (1996). Warning design: A research prospective. London: Taylor & Francis. A thorough account of the emerging applied psychology of auditory warning design.
✵ Yost, W.A., Popper, A.N. and Fay, R.R. (eds). (2008). Auditory perception of sound sources. New York: Springer. With good coverage of some basic psychophysics as well as the higher-level auditory processes, this book covers the recent research on perception of sound sources in humans and animals.