An Introduction to Applied Cognitive Psychology - David Groome, Anthony Esgate, Michael W. Eysenck (2016)
Chapter 3. Face identification
Richard Kemp and David White
3.1 INTRODUCTION
We have a very impressive ability to recognise faces of the people we know, even when viewing conditions are challenging. When catching a glimpse of a friend on a busy street or discovering an old and dusty photograph of a loved one, people recognise familiar faces quickly, accurately and effortlessly. Accurate person identification is fundamental to normal social functioning, and so our visual system has developed robust processes for recognition. As a result, the study of face recognition is a major topic of study in psychological science and many decades of research have been devoted to understanding the cognitive processes engaged when we recognise a face.
Research has shown that these cognitive processes are specially tuned to face stimuli. For example, experiments show that face recognition is impaired by certain manipulations - such as turning images upside down (Yin, 1969) - more than recognition of other visual objects. Further, brain-damaged patients can display impairment in their ability to recognise faces while being unimpaired in the recognition of other visual objects (Farah, 1996). This neurological evidence has since been corroborated by brain-imaging studies, identifying regions of the brain that are more responsive to face stimuli than to images of other objects (Kanwisher et al., 1997; Haxby et al., 2000). These findings have led to the assertion that our visual systems engage ‘special’ processes when viewing and recognising faces, which has led to the development of cognitive models that are specific to the face processing system (Bruce and Young, 1986; Haxby et al., 2000).
Faces’ ‘special’ status to our perceptual system stems from the abundance of socially important cues that faces transmit and from the fact that faces are the primary route to identifying familiar people in our daily lives (Young et al., 1985). In this chapter, we will summarise research on face identification, with a specific bearing on issues related to the societal importance of face identification. Reliable face identification is of critical importance in a variety of applied settings, such as police investigations, legal proceedings and fraud detection. This is especially true in the modern globalised world, where verifying the identity of people as they cross international borders is increasingly important for national security. Critically, however, in these situations the faces that are encountered are almost always unfamiliar to the viewer, and psychological research shows that this has very profound effects on the accuracy of face identification.
We are very good at recognising the faces of people we know, but surprisingly poor at identifying unfamiliar faces. To demonstrate this, we invite the reader to estimate how many people are pictured in Figure 3.1. Jenkins and colleagues set this task to a group of UK students who were unfamiliar with the faces pictured in the array, asking them to sort the images into piles so that in each pile there was a single identity and there was a different pile for each identity (Jenkins et al., 2011). On average, participants who were unfamiliar with the faces in the array made seven piles, indicating that they thought there were seven people in the array. However, participants who were familiar with the faces all correctly decided that there were only two people present in the array. This study demonstrates the difficulty of unfamiliar face matching, and also why it is difficult. When participants were unfamiliar with these faces, they consistently mistook changes in the image (e.g. due to head angle, expression and lighting) for changes in identity. Interestingly, early studies of face memory often tested recognition accuracy on precisely the same images that were presented in the study phase (e.g. Yin, 1969). As a result, these studies overestimated accuracy in unfamiliar face identification. It is well established that our memory for images is very good. As Figure 3.1 shows, this is not the task faced outside of the psychology lab - where the challenge is to identify faces across images that are highly variable in appearance.

Figure 3.1 How many people are pictured in this array? The answer is provided in the text below (full solution is provided at the end of this chapter).
Source: reprinted from Jenkins et al. (2011), copyright 2011, with permission from Elsevier.
We begin this chapter by introducing research on eyewitness identification (Section 3.2). As will be seen, the precise methods used to probe witnesses’ memory turn out to have a very significant impact on the accuracy of face identification, and ultimately on the outcome of criminal trials. In Section 3.3 we then briefly summarise research on facial ‘composite’ systems that are used as a tool to assist criminal investigation to reconstruct the facial likeness of suspects from the memory of witnesses. In Section 3.4 we turn to face identification tasks that do not involve memory but rather involve matching images of faces that are presented simultaneously. Although this task may sound straightforward, research consistently shows that identifying people in this way can be a very difficult task. In Section 3.5, we set this research within the context of modern identification systems. Face identification in applied settings is increasingly supported by automatic face recognition software and images of our faces are being captured at an ever-increasing rate, by smartphones, CCTV cameras and biometric systems. This trend is likely to have a large impact on the type of research questions being asked by future generations of researchers in this field.
3.2 EYEWITNESS IDENTIFICATION
Imagine that you are a witness to a crime. Two weeks later the police contact you to say they have arrested someone in connection with the offence and would like you to visit the station to see if you can identify the offender. When you arrive, you are shown the faces of six similar-looking men. How well do you think you would do? You might feel confident about your ability to identify the offender, but a recent analysis of the performance of real witnesses to real crimes in several different US police districts (Wells et al., 2015) suggests that about 60 per cent of witnesses don’t select anyone from the lineup, and another 15 per cent pick someone other than the suspect (and are therefore known to be making an error). This leaves just 25 per cent of real witnesses who will identify the police suspect. This low rate of suspect identification is worrying in that it represents a loss of important evidence that may leave criminals free to re-offend. More worryingly, psychological research conducted over the past few decades also shows that some identifications made by eyewitnesses will be inaccurate, leaving a guilty person to go free and an innocent person convicted of an offence they did not commit. In this section we will review the progress of psychological research on eyewitness identification and the attempts by psychologists to help police develop more effective eyewitness identification procedures.
DANGEROUS EVIDENCE: EYEWITNESS IDENTIFICATION
If the police investigating a crime have a witness and a suspect, they will arrange an identification procedure. Identification procedures are the mechanisms used by police to collect evidence regarding the identity of the perpetrator. Regardless of the precise procedure used, jurors find identification evidence very compelling and an eyewitness’s positive identification of a suspect dramatically increases the probability that a jury will convict (Leippe, 1995). It is because eyewitness identification evidence is so compelling that it is also so dangerous. As we shall see, identification evidence provided by an honest witness can be sincere, confident, convincing - and wrong.
EYEWITNESS IDENTIFICATION PROCEDURES
Police and investigators may use a number of different identification procedures, but common to all is that they involve collecting memory evidence from a witness to test the hypothesis that the suspect is the perpetrator of the offence being investigated. This evidence may be used to further the investigation, or it may form part of the prosecution case presented in court. In many jurisdictions the most commonly used identification procedure is a photographic array or lineup, in which the witness is shown an image of the suspect together with a number of ‘foils’ or ‘fillers’ - people the police know to be innocent. The details vary between jurisdictions; for example, witnesses are typically shown six faces in the US, while a nine-person lineup is more common in the UK, and in New South Wales, Australia, lineups often include as many as twenty people. In some countries the procedures are tightly controlled by legislation (for example, the UK), while in many US states there are non-binding guidelines leading to large differences between, and even within, states (National Academy of Science, 2014). British police used to make widespread use of live lineups - sometimes referred to as identification parades (e.g. see Figure 3.3) - however, these are difficult and expensive to organise and have now been replaced by video-based procedures (Kemp et al., 2001).
Sometimes police don’t have sufficient evidence to arrest a suspect in order to undertake a lineup. In these cases they may use procedures, such as showups, where the witness is shown the suspect and asked ‘Is that the person you saw?’, or ‘field identifications’ in which the witness is exposed to the suspect in an uncontrolled environment. For example, in one high-profile Australian case the witness sat with a police officer in a court waiting room on the day the suspect was attending court in relation to another matter, and the witness was asked to indicate if she saw the perpetrator among the people coming and going. If police don’t have a suspect, they may ask a witness to look through ‘mug books’ containing the photographs of individuals responsible for similar offences, and an interesting recent development has been the emergence of cases in which suspects were identified by witnesses looking through images posted on social media sites such as Facebook (see National Academy of Science, 2014).
Box 3.1 The Innocence Project: A window on error rates in the legal system
We normally think of DNA evidence being used to prove the guilt of an offender, but this technology can also prove innocence. The world’s first conviction involving DNA evidence occurred in the UK in 1986, and just 3 years later, in 1989, a US court was the first to use DNA evidence to prove the innocence of a previously convicted person. Three years after this, in 1992 two law professors, Barry Scheck and Peter Neufeld from Yeshiva University in New York, established the Innocence Project, a not-for-profit organisation which sought to use DNA evidence to prove the innocence of wrongfully convicted people. Over the next 24 years a total of 329 people in the USA were exonerated on the basis of DNA evidence, and an analysis of the cases which led to these erroneous convictions has been an important spur both for applied psychology research and for policy reform around the world.
The people exonerated through the work of the Innocence Project served an average of 13.5 years in prison, with eighteen serving time on death row before being released. What quickly became apparent is that many of these cases have factors in common. For example, around 70 per cent of those exonerated are from ethnic minorities (African American, Latin or Asian). It is also apparent that certain types of evidence are common features of many of the cases. As can be seen from Figure 3.2, around three-quarters of these cases have involved eye witness misidentification. That is, in well over 200 of these cases at least one witness stood up in a US courtroom and gave sworn and (presumably) sincere evidence that they could identify the accused as the person who committed the offence. In each of these cases the witnesses were wrong.
In one of the early cases, five apparently independent witnesses each testified that Kirk Bloodsworth was the person they had seen with a young child before she was murdered. They were wrong, but Bloodsworth almost paid for their error with his life when he was sentenced to death. The emergence of this evidence of factual innocence in people convicted of very serious offences (90 per cent are sex offences, 30 per cent involve homicide) has had an enormous influence on psycho logical research in this field, providing researchers with irrefutable proof that eyewitness errors occur not only in the laboratory but also in the real world where the consequences can be tragic. This work has also had a significant impact on public policy, particularly in the USA where, following these cases, many states have suspended use of the death penalty.
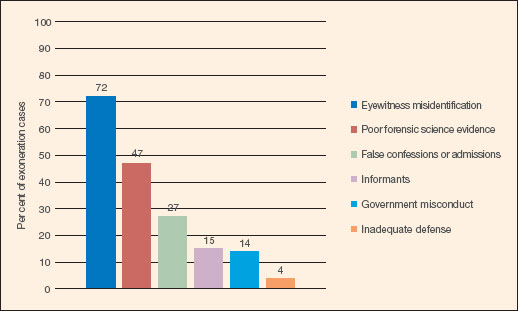
Figure 3.2 Contributing causes in the first 329 DNA exoneration cases. Note columns sum to more than 100 per cent because most cases have more than one cause.
Source: drawn using data from www.innocenceproject.org.
The reader is encouraged to visit the excel lent Innocence Project website (www.innocenceproject.org) and to watch some of the organisation’s informative videos (search YouTube for ‘innocence project eyewitness evidence getting it right’).
RESEARCHING THE FACTORS AFFECTING IDENTIFICATION ACCURACY
The accuracy of eyewitness identification evidence has been a major focus of applied psychological research for several decades, with a very large number of laboratory studies employing the same basic methodology in which participants view a to-be-remembered event (often a video of a staged crime). After a delay of between a few seconds and a few weeks, the participants are asked to identify the perpetrator using some form of identification procedure. The experimental variable under investigation might be manipulated during the to-be-remembered event (for example, by allocating participants to different lighting conditions) or during the identification process (for example, allocating participants to different identification procedures). The dependent variable in these studies is identification accuracy, which can be measured in several different ways (more on this later).
Well-designed studies in this field will include both target-present and target-absent identification procedures. We know that police investigators will sometimes make a mistake and put an innocent suspect in a lineup, so it is important that researchers measure the ability of witnesses to recognise that the perpetrator is not present in a lineup using a targetabsent lineup.
SYSTEM VARIABLES AND ESTIMATOR VARIABLES
An important early contribution to applied eyewitness identification research came from Wells (1978), who encouraged researchers to distinguish between system and estimator variables. Estimator variables are those factors which, although affecting the accuracy of identification evidence, are not under the direct control of the criminal justice system. For example, identification accuracy is affected by the distance and lighting conditions (see below), and although this information might help us estimate witness accuracy after the fact, there is nothing we can do with this knowledge to improve accuracy of future identifications. In contrast, system variables are under the control of policy makers. If we determine that the manner in which the police conduct an identification procedure affects the accuracy of the evidence collected, we can take action to modify the procedures in light of this research and thus improve the quality of the evidence presented in court. Wells argued that psychologists should concentrate their research on system variables, as this allows the research to inform the development of policy. As a result, much of the more recent research has focused on system variables, and this is where some of the most vigorous debate has occurred within the literature. However, before focusing on system variable research we will briefly review some of the key estimator variables.
ESTIMATOR VARIABLES
Many different estimator variables have been identified as affecting identification accuracy. These include factors relating to the exposure to the to-be-remembered event. For example, Wagenaar and Van Der Schrier (1996) systematically studied how identification accuracy varied with changes in lighting and distance, and suggested that accurate identification was unlikely when a face was viewed at more than 15 metres or at an illumination level of less than 15 lux. Exposure duration, or the time the witness observes the perpetrator, has also been investigated. A recent meta-analysis examined the results of thirty-three studies involving almost 3,000 participants and found that, for relatively short exposures, longer durations resulted in better identification accuracy, but that this relationship broke down with relatively longer exposure durations (Bornstein et al., 2012).
Other researchers have investigated how characteristics of the witness affect identification accuracy. Critical among these estimator variables is stress. Real eyewitness events are often (but not always) stressful, but it is difficult and potentially unethical to reproduce in the lab the fear experienced by these witnesses. Some researchers have found imaginative ways around this problem. For example, Valentine and Mesout (2009) measured the heart rate of participants as they walked around a horror exhibit at the London Dungeon at which they encountered an actor dressed as a ‘scary person’. Later they tested participants’ ability to describe and recognise the actor. Those who reported high stress gave less accurate descriptions and were less likely to identify the actor correctly from a nine-person lineup. The effect of stress on identification accuracy was dramatic, with only 17 per cent of participants who reported high levels of stress accurately identifying the actor compared with 75 per cent of those who experienced lower levels of stress. A meta-analytic review of studies of the effect of stress on identification accuracy (Deffenbacher et al., 2004) found a similar, but more modest-sized relationship between stress and accuracy.
A possibly related phenomenon is the ‘weapon-focus effect’, whereby witnesses who observe a perpetrator holding a weapon have been found to make fewer accurate identifications than those who see no weapon (see Steblay, 1992; Fawcett et al., 2013). To avoid the obvious ethical pitfalls facing research in this field, some scientists have developed very imaginative tests of the effect. For example, Maass and Köhnken (1989) asked participants to try to identify a nurse who had talked to them while holding either a large syringe (weapon) or a pen (no weapon) and who either had or had not threatened to inject them. Approximately 66 per cent of the participants who saw the syringe made a false identification from the seven-person target-absent lineup, compared with 45 per cent of those who saw the pen. Interestingly, the effect of the threat of being injected was not significant, and this is in line with other studies which have suggested that the weapon-focus effect may be caused more by the attention-grabbing nature of the weapon than by the stress the presence of a weapon may induce. For example, Mitchell and colleagues (1998) found that eyewitness recall for the appearance of a perpetrator was impaired as much by seeing the man brandishing a stick of celery as when he was seen with a gun. However, in a recent meta-analytic review, Fawcett et al. (2013) found the effect was moderated by several factors and was strongest when the threat level was high, when the weapon was visible for a moderate amount of time (between 10 and 60 seconds) and when memory was tested immediately after exposure.
Another estimator variable which has attracted some attention is the race of the witness relative to the perpetrator, in an effect known as the own-race bias (or the cross-race effect or other-race effect). A large body of research has consistently shown that participants are often more accurate at recognising members of their own racial group than people from another group. A meta-analysis of the research (Meissner and Brigham, 2001) concluded that participants are 1.4 times more likely to correctly identify an own-race than another-race face, and 1.56 times more likely to mistakenly identify an other-race face compared with an own-race face. There is also archival evidence to suggest that this effect has contributed to some false convictions. The Innocence Project (2015; see Box 3.1) has estimated that about three-quarters of DNA exoneration cases involve mistaken eyewitness identification evidence, and in about half of all those cases the erroneous identification was made by a witness identifying a suspect of another ethnicity. The cross-race effect may also interact with other factors. For example, alcohol intoxication appears to reduce the magnitude of the effect (Hilliar et al., 2010), while short exposure duration exacerbates it (Meissner and Brigham, 2001).
SYSTEM VARIABLES, EYEWITNESS IDENTIFICATION AND POLICY CHANGE
The impact of a number of system variables on eyewitness identification accuracy has been a major focus for researchers in recent years. This research has been driven by a strong desire to inform the development of policy in this field with the hope of limiting the number of false identifications made by eyewitnesses, both to reduce the number of erroneous convictions and to increase the likelihood of convicting guilty perpetrators. The process of achieving policy change is difficult and often causes controversy among scientists who may disagree about which recommendations to put forward. Despite this, during the early years of this century there was some degree of consensus among psychologists working in this field, but in the past few years this consensus has dramatically broken down, and there have been direct challenges to many long-held beliefs regarding best practice in lineup procedures. In this section we trace out this sequence of events.
Box 3.2 Psychologists as expert witnesses
Given the growing understanding of the factors affecting eyewitness identification accuracy, psychologists are sometimes asked to appear as expert witnesses to help courts understand the research as it applies to the facts of the case under consideration. For example, a psychologist might be asked to describe what is known about the effect of stress on eyewitness memory. This can be a challenging role for psychologists; the court room is an alien environment for academic researchers, and the legal process isn’t always compatible with the scientific method. Some researchers have considered the question of whether this type of expert testimony is actually helpful to jurors. Martire and Kemp (2011) tested the impact of expert evidence on the ability of participant-jurors to determine whether a witness had made an accurate identification. They distinguished between three possible outcomes: sensitivity, where the expert’s evidence enhanced the ability of jurors to distinguish accurate from inaccurate identifications; scepticism, where the evidence led the jurors to mistrust all eyewitness evidence regardless of its accuracy; and confusion, where the expert had no clear impact on the jurors’ decision making (see also Cutler et al., 1989). They noted that previous studies had found mixed results, but that most studies had employed a ‘fictional’ eyewitness design in which participants viewed actors playing the role of eyewitnesses. Martire and Kemp (2009) employed a ‘real’ eyewitness design, in which participant-witnesses who had seen an event, and then attempted to make an identification from a lineup, were cross-examined. A recording of this crossexamination was then presented to the participant-jurors. Using this complex but more sophisticated design, Martire and Kemp found expert evidence had no discernible effect on the ability of the jurors to distinguish accurate from inaccurate eyewitness evidence. Does this mean that psychologists shouldn’t give evidence in court? This is a complex issue, but it is important to note that Martire and Kemp only examined one particular form of expert evidence (see also ‘The CCTV problem’, Section 3.4). The jury is still out on this issue.
In 1998, the executive committee of the American Psychology-Law Society solicited a report that would recommend improvements in the practices used to conduct identification procedures (Wells et al., 1998). The report, often referred to as the ‘Lineups White Paper’, recommended four guidelines for identification procedures:
1 The lineup administrator should be blind to the identity of the suspect.
2 The witness should be warned that the perpetrator might not be present.
3 The fillers (i.e. the persons or photographs of persons other than the suspect) should be selected to match the witness’s verbal description of the perpetrator.
4 The witness should be asked to describe his or her confidence in his or her identification immediately after the identification is made.
The first recommendation was designed to avoid the possibility that the administrator might inadvertently influence the witness’s identification decision, and this is in line with best practice in many fields of research that require the use of double-blind designs. The second requirement was also uncontroversial, and was justified by reference to research showing that witnesses make fewer false identifications when instructed that they can respond ‘not present’ (e.g. Malpass and Devine, 1981). The third recommendation was that fillers (or ‘foils’) be matched, not to the appearance of the suspect, but to the verbal description provided by the witness. This is based on research (e.g. Wells et al., 1993) showing that when only a few members of the lineup resemble the description provided by the witness, the rate of false identification rises compared with when all lineup members match the verbal description. Wells et al. argued that matching foils to the witness’s verbal description rather than the suspect’s appearance would result in lineups that were fair to the suspect while avoiding the situation where a witness is confronted with a line of ‘clones’ who all look very similar to each other and to the suspect.
The fourth recommendation was that the witness’s confidence in their identification decision should be recorded. This was motivated by the observation that jurors and legal professionals find confident witnesses more convincing (e.g. Cutler et al., 1990; Brigham and Wolfskeil, 1983; Noon and Hollin, 1987), but that a witness’s confidence in their identification is malleable and may change over time and can be inflated by subtle clues and feedback about their performance (Luus and Wells, 1994). It was hoped that a record of the witness’s confidence at the time they made the identification, before any feedback was provided, would help to counter some of these effects and provide a less misleading measure of witness confidence.

Figure 3.3 A traditional police lineup. Modern versions of these identification procedures have been heavily influenced by psychological research.
Source: copyright Everett Collection/Shutterstock.com.
SIMULTANEOUS AND SEQUENTIAL IDENTIFICATION PROCEDURES
Wells et al. (1998) stated: ‘were we to add a fifth recommendation, it would be that lineup procedures be sequential rather than simultaneous’ (p. 639). The distinction between these two forms of the identification procedure, and the relative merits of both, have recently become a focus of considerable debate, but at the time of the publication of the white paper the evidence appeared to strongly favour the adoption of the sequential parade.
In a conventional or simultaneous identification procedure, the witness is able to view all the lineup members at once and can look at each member any number of times before making a choice. In the sequential identification procedure devised by Lindsay and Wells (1985), the witness is shown the members of the lineup one at a time and must decide whether or not each is the target before proceeding to consider the next lineup member. Sequential presentation does not permit visual comparison of lineup members with each other, and the witness cannot view all members of the lineup before making a match decision. This procedural change was designed to encourage the use of a more ‘absolute’ strategy where the witness compares each member of the lineup with his or her memory of the perpetrator. This is in contrast to a ‘relative’ strategy used in simultaneous presentation, which may result in selecting the person most like the perpetrator, leading to more false identifications in target-absent lineups. In their initial evaluation Lindsay and Wells (1985) found that for target-absent lineups the rate of false identification was very much lower using the sequential than the simultaneous procedure (17 versus 43 per cent).
Since this publication, many studies comparing these two procedures have been conducted. A meta-analytic review of thirty studies found that participants who viewed a target-absent lineup were less likely to make a false identification when the sequential procedure was adopted compared with the simultaneous procedure (Steblay et al., 2001). However, it has also become clear that this sequential advantage comes at a cost: sequential lineups also result in fewer correct identifications when the target is present. This pattern of results has been confirmed with a recent analysis (Steblay et al., 2011): relative to the conventional simultaneous procedure, sequential lineups reduce the number of false identifications in target-absent lineups, but also result in fewer correct identifications in target-present lineups. This pattern of results is now well established but a fierce argument has recently broken out over how best to interpret these data.
MEASURING THE UTILITY OF IDENTIFICATION PROCEDURES
Until recently, many studies measured the accuracy of identifications made under different conditions by computing a measure known as the ‘diagnosticity ratio’, which is the ratio of hits (correct identifications of the target) to false alarms (incorrect identifications of a foil). This has been taken as a measure of the likelihood that an identification made by a witness is correct. However, there is a significant problem with this measure because its magnitude can be increased in two ways: by an increase in correct identifications, or by a reduction in false identifications. As a result, it can be difficult to interpret studies that report only this measure and to translate their practical implications.
In particular, the use of this measure to compare simultaneous and sequential lineups has come under fierce criticism recently. In their meta-analysis Steblay et al. (2011) found that sequential lineups have higher diagnosticity ratios than simultaneous lineups, and on this basis they argue for the superiority of sequential lineups. However, alternative measures of performance can lead to different interpretations. One promising approach is the use of signal detection theory to analyse data from eyewitness identification studies (see National Academy of Science, 2014). This approach allows researchers to separate out two distinct aspects of the identification process. The first of these is discriminability - which in this context is the extent to which participants were able to distinguish between targets and foils. The second measure is response bias, which is a measure of the tendency for participants to make ‘target present’ responses relative to ‘target absent’ responses. Using this approach, Mickes et al. (2012) have argued that simultaneous lineups are superior to sequential as they result in higher discriminability. Also using a signal detection theory framework, Gronlund et al. (2014) argued that sequential lineup procedures simply shift a witness’s response bias so they make fewer identifications in general, without improving discrimination. Witnesses tested under the sequential system, they argue, are less likely to select foil identities from a lineup simply because they are less likely to select anyone from the lineup.
This has not been the only reversal for those advocating the sequential lineup. Malpass (2006) argued that we have placed too much emphasis on the reduction of false identifications, and have ignored the fact that simultaneous lineups result in more correct identifications of the perpetrator when they are present. In a thoughtful analysis, Malpass attempted to model the circumstances under which the different lineups would have greater utility. He concluded that, unless we assume that over 50 per cent of all police lineups are target absent (which seems very unlikely), in many circumstances the simultaneous lineup is actually prefer able because of the greater hit rate it will afford.
Another significant problem for the advocates of sequential lineups came in the form of a test of lineup procedures conducted in several police districts in the state of Illinois. This study, which has become known as the ‘Illinois field study’, set out to compare the performance of real eye witnesses in conventional non-blind simultaneous lineups and double-blind sequential lineups (Mecklenburg et al., 2008). The study found that witnesses were more likely to erroneously identify a foil in a sequential lineup than in a simultaneous lineup (9.2 vs 2.7 per cent respectively). These findings generated enormous controversy and very fierce criticism of the study methodology. Steblay (2011) describes how she used freedom of information legislation to require the study authors to hand over data for re-analysis. Steblay concluded that the study was fatally flawed because the allocation of cases to the two lineup conditions was non-random, with systematic differences between the cases assigned to sequential and simultaneous lineups.
Possibly the best outcome from the controversy surrounding the Illinois field study is that it motivated some researchers to set up more valid field tests. Wells et al. (2015) report the early results of a particularly interesting field trial (known as the AJS trial) in which researchers have provided police with computers programmed to allocate cases randomly to either simultaneous or sequential lineups, which are then conducted under very tightly controlled conditions. The data from these real identification procedures were logged by the computers and analysed by the researchers. Initial data from almost 500 eyewitnesses show no differences in the rates of suspect identification (25 per cent overall), but sequential lineups resulted in significantly lower rates of erroneous foil identification (11 per cent) compared with simultaneous lineups (18 per cent). Thus, these data slightly favour the use of sequential lineups over simultaneous lineups.
It should be clear by now that the previous consensus about the use of sequential lineups no longer holds, and that we need to consider any future policy recommendations carefully. It is admirable that we want to use our research to inform policy change in this important area of the law. However, we can’t afford to change that advice too often or the policy makers will lose patience with us. We must consult widely and consider all the implications of any changes we recommend.
3.3 MAKING FACES: FACIAL COMPOSITE SYSTEMS
If the police have a witness but not a suspect, they will often ask a witness to describe the perpetrator in order to construct a pictorial likeness. In past years the witness would describe the perpetrator to a police artist who would make a sketch, but in more recent years this process has been assisted by the use of ‘facial composite systems’.
The first widely adopted composite system in the US was Identikit, which comprised large collections of drawings of features. The UK system, Photofit, was similar except that it used photographs of features. Using these systems, witnesses could browse catalogues of features to select the eyes, nose, hairline etc. that best matched their memory of the perpetrator’s appearance. The composite could be enhanced with hand-drawn additions. Early tests of these first-generation composite systems (Ellis et al., 1978; Laughery and Fowler, 1980) were not encouraging, in that likenesses constructed while looking at the target were not rated any better than those made from memory, suggesting that the systems were incapable of producing good likenesses. Christie and Ellis (1981) suggested that the composite systems were essentially worthless and police may as well hand witnesses a pencil and paper and ask them to draw the likeness themselves.
With the advent of personal computers, a second generation of composite systems was developed in the 1990s, which replaced paper features with computer image files. One British system, E-Fit, was designed to reflect recent psychological research about face perception. First-generation systems required the witness to select a feature in isolation from the face, for example searching through a catalogue of eyes looking for a match to the perpetrator. This approach is problematic because we don’t see faces as a collection of features; rather, we see a face as a single perceptual unit (Young et al., 1987). Not even a composite operator remembers a friend as someone with a number 36 nose and 12b eyes! For this reason, in the E-Fit system the witness never views the features outside the context of the whole face. The operator interviews the witness and enters the description into a series of text screens containing standardised feature descriptions. The system then constructs a likeness based on this description and shows it to the witness, who can then modify and enhance it.
The evaluations of these second-generation composite systems were also more sophisticated. When the police publish a composite, they also release other details of the offender and the offence in the hope that someone who is familiar with the perpetrator will see the image and recognise it as a ‘type-likeness’ of someone who also matches other aspects of the description. The police report that the people who recognise composites are usually people familiar with the offender, not strangers. For this reason, evaluations of composite systems should measure how often participant-judges spontaneously recognise a familiar face from a composite. Using this approach, Brace et al. (2000) measured the ability of undergraduates to name a set of E-Fit composites of famous people produced either from memory or working from a photograph. The majority of the composites were spontaneously named by at least one of the judges, and some composites were recognised by almost all participants.
In the past decade a third generation of composite systems has emerged (see Frowd et al., 2015). With systems such as EvoFIT and E-FIT-V the witness is presented with an array of faces from which they are asked to select the images most similar to the person they saw. The selected images are then ‘bred’ together to evolve a new set of likenesses which are presented to the witness who again selects the best likenesses (see Figure 3.4). In this way the witness works towards a likeness of the person they saw. The witness can also make some global adjustments to the face, for example ageing it appropriately. The images produced by these latest systems look realistic, and a recent meta-analysis of the published studies (Frowd et al., 2015) suggests that these third-generation systems produce better likenesses which are correctly named more than four times as often as composites produced using a first-generation, feature-based approach. In one recent study (Frowd et al., 2013), a third-generation composite system, used in combination with other techniques, including a modified version of the cognitive interview (see Chapter 8), produced likenesses that were correctly named by participants in up to 73 per cent of cases. Thus, it appears that the application of psychological research has helped us produce facial composite systems which are likely to be of much greater value to police.
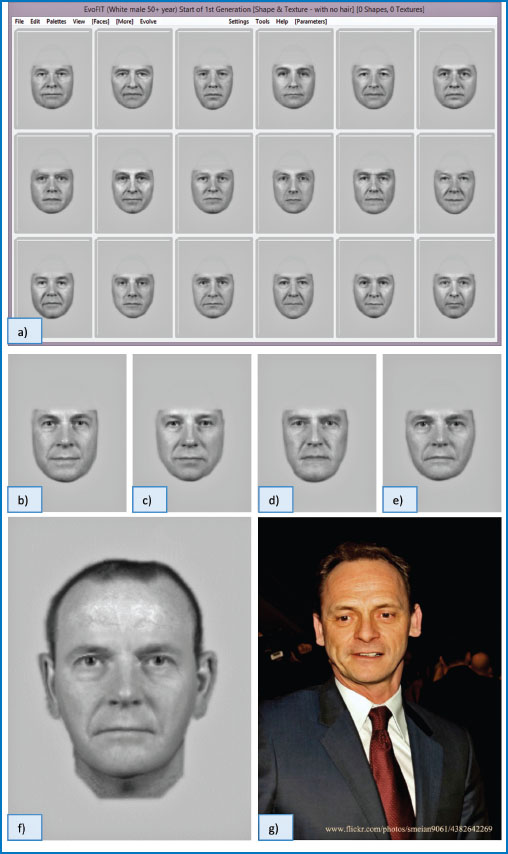
Figure 3.4 The construction of a facial composite using EvoFIT, one of the new generation of composite systems. In this example a witness is attempting to construct from memory a likeness of TV character Billy Mitchell (actor Perry Fenwick from the BBC television series Eastenders). Part a) shows a section of the initial array of computer-generated faces which is shown to the witness who selects those most like the target. These faces are then ‘bred’ together to produce a new set of images and this process is repeated four more times, parts b), c), d) and e), before hair and a face outline are added in part f) to produce the final likeness. The composite can be compared to the photograph of Perry Fenwick (part g).
We thank photographer Ian Smith for making the photograph of Perry Fenwick available under a Creative Commons licence. Thanks to Charlie Frowd for providing and allowing reproduction of the other parts of this image.
3.4 UNFAMILIAR FACE MATCHING
At this point in the chapter it should be clear that our memory for faces of unfamiliar people is unreliable, as shown by very poor identification accuracy in lineup tasks. This problem is further complicated when police are required to extract a representation of a suspect from the memory of a witness. Despite the very sophisticated methods for creating facial composites, success rates for identification using these techniques remain quite low.
So, is the problem of face identification a problem of memory and initial encoding difficulties? If this is true, perhaps we can solve the problem by removing the burden of memory? This reasoning seems to be behind increased deployment of CCTV in city streets - providing a photographic record of a person’s appearance that can then be compared with suspects in criminal proceedings. Although this task appears to be straightforward, research conducted since the late 1990s has consistently shown that people are surprisingly poor at this task.
In this section we review literature on face identification tasks that do not involve memory. As the Bruce et al. study (1999; see Figure 3.5) shows, performance in identifying unfamiliar faces is surprisingly poor even when there are optimal conditions for matching. Why were people so poor on this apparently straightforward task? One critical factor may have been that the two images were taken with different cameras, which is sufficient to introduce subtle differences in the appearance of the images. Subsequent research has shown that small differences in head angle, expression and lighting direction, while having undetectable effects on familiar face recognition, can cause significant impairments in our ability to match images of unfamiliar faces (Bruce, 1982; Hancock et al., 2000).
THE PASSPORT PROBLEM: CHECKING PHOTO-ID
In everyday life we are often asked to provide photo-ID to verify our identity. Matching faces to photographs on these documents is a commonplace task: immigration officers verify identity at national borders, bank tellers secure financial transactions and shop owners confirm that young adults are of legal age - all by comparing faces with photographs contained on identity cards. Because the process of matching faces to photographs is such an integral part of identity verification in our society, one would hope that people could perform it accurately. Astonishingly, despite the fact that photo-ID has been used to identify people since the early twentieth century, the first test of this ability was not conducted until the late 1990s (Kemp et al., 1997). In this study, Kemp and colleagues carried out a field test to assess the potential for including photos on credit cards as a fraud detection measure. They provided student volunteers with identity cards that contained images either of their own face or of the face of a similar-looking person. This method enabled them to test the ability of supermarket cashiers to detect non-matching ‘fraudulent’ credit cards. The supermarket cashiers were surprisingly poor at this task - falsely accepting 50 per cent of ‘fraudulent’ cards.
Box 3.3: Eyewitness memory without the memory
In a classic study, Bruce and colleagues (1999) produced lineup arrays that simulated identity parades. The design of this study was broadly similar to the simultaneous lineup arrays used in studies of eyewitness memory, described in Section 3.3 (this chapter). However, in this study the target was displayed directly above the lineup (see Figure 3.5). This has the effect of removing the memory component of eyewitness memory tasks, providing an important test of ‘baseline’ accuracy on face identification without memory. Surprisingly, participants in this test performed very poorly - making errors on 30 per cent of trials. This result has been replicated in a number of studies since this initial paper, using variations on this task format. For example, Megreya and Burton (2008) also show that performance on this task remains very poor, even when identifying a person that is standing directly in front of the participants.

Figure 3.5 Can you find the target face in the array shown? Participants in Bruce and colleagues’ classic study had to decide if the target identity (top) matched any of the identities in the array below and if so they had to select the matching face. On average, participants made 30 per cent errors on this task, despite images all being taken on the same day and under very similar lighting conditions. The correct answer in this example is provided at the end of this chapter.
Source: reproduced from Bruce et al. (1999). Copyright © 1999 American Psychological Association. Reproduced with permission.
It is possible that supermarket cashiers are not accustomed to making many identity checks in their daily work; in professions where face matching is more critical, and training is provided, perhaps performance will be better? A more recent field study tested this by measuring the performance of passport officers in face matching. In this study (White et al., 2014a), passport officers were found to have error rates when verifying photo-ID equivalent to those of untrained student participants, suggesting that their special experience and training was not sufficient to improve their matching performance.

Figure 3.6 Example photo-ID for the photo-to-person face-matching test completed by passport officers in White et al. (2014a). Example valid ID-photos (left column) are shown alongside ‘invalid’ photos of foil identities (right column). Invalid cards, representing cases of identity fraud, were accepted by passport offices on 14 per cent of trials.
Source: reproduced from White et al. (2014a) under a Creative Commons licence. Copyright © 2014 White et al.
The most common error that passport officers made in White and colleagues’ study - and also in the earlier Kemp et al. study - was to falsely accept an invalid image as being of the card-bearer. This is precisely the type of error passport officers would hope to avoid when protecting against identity fraud. These errors were all the more concerning because of the method of selecting ‘foil’ identities in this study. For invalid cards, students were paired with the most similar-looking identity in the group of thirty-two students (half of whom were male and half female; see Figure 3.6). This represents a particularly unsophisticated method for selecting someone that looks like you, roughly equating to swapping identity cards with the most similar-looking person in a sports team. Yet passport officers incorrectly accepted 14 per cent of these cards as valid. The implication of this result is that limits of human perceptual performance represent a very real vulnerability in security checks. We have termed this issue the ‘passport problem’.
However, the ‘real-world’ passport problem is likely to be exacerbated by a milieu of other factors that cause errors in this task. For example, when attempting to commit identity fraud, assailants are likely to go to more extreme lengths compared with the students in the passport officers’ study - by altering their appearance to appear more like their adopted identity. Further, images in both photo-ID field studies (Kemp et al. 1997; White et al. 2014a) were all taken within a few days of the test. However, many photo-ID documents - including passports - are valid for many years, and so passport officers often have to match faces to photographs taken many years ago. Indeed, when White and colleagues re-tested matching performance using pairs of images taken two years apart, performance was far worse - dropping by 20 per cent overall (White et al., 2014a; see also Meissner et al., 2013; Megreya et al., 2013).
Box 3.4: Secure identification at national borders
Verifying the identity of travellers during international travel is increasingly important in our modern world. Given the research reviewed in this chapter which suggests that photo-ID may not be fit for purpose (Figure 3.7), you might expect there to be significant pressure to find an alternative means of identifying people at national borders. In the post-9/11 world governments around the globe have spent a large amount of money with the aim of modernising identity verification processes using a variety of computer-based biometrics (e.g. face, fingerprint, iris etc.). The United States alone has spent over a trillion dollars on homeland security since the World Trade Center attacks of 2001, with the annual budget increased by 300 per cent in real terms. However, despite consideration of a variety of different biometrics, in 2007 the International Civil Aviation Organisation (ICAO; the body that sets the rules for passports and other travel documents) chose facial images as the primary biometric identifier for use in e-Passport documents. This means that for the foreseeable future, facial images will continue to be used to identify people at borders, with computers and humans making identity verification decisions conjointly.

Figure 3.7 Fraudulent passport identities threaten security.
Source: copyright karenfoleyphotography / Shutterstock.com.
However, computers don’t solve the passport problem completely (see Section 3.5, this chapter). So why continue using faces? ICAO cited three main reasons for their decision. They noted that the face is a culturally accepted biometric that is less intrusive than some alternatives, and has been used to identify people for a great many years, thus affording continuity with existing data. More surprisingly, and apparently at odds with the literature described in this chapter, they also reasoned that ‘human verification of the biometric against the photograph/person is relatively simple and a familiar process for border control authorities’ (MRTD Report, 2 (1), p. 16). Psychological research on this topic is very clear that face matching only appears simple - people are surprised to learn how difficult it is. For example, a recent study by Ritchie and colleagues (2015) asked participants to predict how difficult face-matching decisions would be for the general population. Participants in this task consistently rated the difficulty of the matching decision as lower when they themselves were familiar with the faces, and so perhaps the intuition that face matching is easy is based on the ease with which we identify familiar faces (see Figure 3.8). It is possible that the ICAO decision was also based on this incorrect intuition.

Figure 3.8 Are these image pairs of the same person or different people? The image pair on the left (A) is an item from the Glasgow Face Matching Test (a standardised test of unfamiliar face-matching ability; Burton et al., 2010). If you are familiar with the current UK prime minister, the answer to the image pair on the right (B) should be obvious. Answers are provided at the end of this chapter.
Source: (A) reproduced from the Glasgow Face Matching Test with permission from Professor Mike Burton. (B) We thank Mattias Gugel and Guillaume Paumier for making the images available on a Creative Commons licence.
To compound this problem, it is rare for people to commit identity fraud, and so it is also uncommon for people who are required to check images of faces on a regular basis to be presented with cases of mismatching faces. In 2006 the UK Home Office estimated that the rate of fraudulent passport applications was 0.25 per cent. Identity fraud is presumably low in many other critical security checks where punishments for detected imposters are severe, such as at border control. For passport officers and others working in similar roles, this is further reason to believe that face-matching tasks are more difficult in many real-world identity checks than in scientific tests.
The reason that the field tests may underestimate the problem is that, in both the studies carried out by Kemp and colleagues (Kemp et al., 1997) and White and colleagues (White et al., 2014a), participants presented invalid photo-ID on 50 per cent of trials. In a computer-based study, Papesh and Goldinger (2014) showed that detection of non-matching face pairs in a ‘low-prevalence’ condition, where non-matches appear rarely (on 10 per cent of trials), is far poorer than when non-matching pairs were presented in a ‘high-prevalence’ condition in which non-matching ID were encountered on 50 per cent of trials. Participants in their study detected 30 per cent fewer fraudulent (i.e. non-matching) ID cards in the low-prevalence condition compared with the high-prevalence condition. This result is consistent with low rates of detection in visual search tasks where targets are only rarely encountered, such as the task performed by airport baggage screening staff (Wolfe et al., 2005).
SOLVING THE PASSPORT PROBLEM
Because people are so poor at matching faces of unfamiliar people to photographs, a possible solution is to reduce reliance on face images by replacing them with more reliable biometrics such as fingerprints or iris scans (but this is not the preferred solution; see Box 3.4). Another solution might therefore be to continue using facial images but to instead reduce reliance on human processing by replacing humans with computer recognition systems. Indeed, this method is favoured by governments across the world, which have invested heavily in automatic face recognition software to replace manual passport checking at border controls and in passport application processing. Importantly, the use of these sophisticated automatic recognition systems does not completely eliminate the need for human processing and in some instances actually increases the burden of human processing (see Section 3.5).
Another possible solution to the passport problem is to develop solutions informed by psychological research. For example, because face matching is a straightforward task when faces are familiar (see Figures 3.1 and 3.8), one route towards photo-ID that can be matched to the card bearer more reliably might be to develop photo-ID that confers some of the benefit of familiarity on the viewer. This is a promising solution because studies have shown that even a little exposure to a face can provide enough familiarity to show significant improvements in accuracy of identification. For example, Megreya and Burton (2006) set participants the same face-matching task used by Bruce et al. (1999; see Box 3.3). However, before half of the face-matching trials, participants were shown short videos of the ‘target’ faces. When participants were familiarised with the faces by watching the videos, their performance in the matching task improved by 13 per cent compared with when they were not shown the videos.
So how might we build familiarity into photo-ID? Modern biometric passports have the capacity to store image data on a memory chip, so one proposal is to use this capability to store multiple images of a face. Single photographs, by their nature, place significant constraints on accuracy in face matching because they represent only a snapshot of a facial appearance (with specific head angle, expression etc.) captured with a particular set of image variables (lighting, distance from camera, aperture settings). Take, for example, the photo array in Figure 3.1 at the beginning of this chapter, where the variation in photographs of the same face caused participants to vastly overestimate the number of people that are included in the array (Jenkins et al., 2011). This represents the type of variation that we encounter from day to day and are easily able to handle in the recognition of familiar faces. For example, the array of photographs in the top row of Figure 3.9 are all easily identifiable to people who are familiar with these celebrities. However, when we encounter unfamiliar faces we appear to be unwilling to accept that all these images might be of the same person.

Figure 3.9 Can you recognise these celebrities? The images on the bottom row are ‘face averages’ created by averaging together multiple images of a person’s face (top row). These representations have been shown to improve face recognition performance in humans (e.g. Burton et al., 2005) and computers (Jenkins and Burton, 2008; Robertson et al., 2015), and may also be an alternative to traditional photo-ID (White et al., 2014b).
Source: adapted from Robertson et al. (2015) under a Creative Commons license. See page 70 [end of chapter] for full photo credits.
One strategy to overcome this problem is to build representations that are suited to matching with a variable input source. A technique that has produced some success was adapted from a method described in the nineteenth century by Francis Galton. Galton created ‘photo composites’ that combined multiple photographs into a single image. The technique used to achieve this was analogous to a primitive version of the ‘layers’ function in Adobe Photoshop, and involved exposing a single photograph plate to a series of face images. This enabled Galton to extract the features common across the various images. While Galton was primarily concerned with extracting similarities across images of different people (for instance to find the features that are common to criminal-types!), this same technique has recently been implemented using digital technology to extract the features that are common to a single face by combining multiple images of the same face by averaging them (Figure 3.9, bottom row). The resulting ‘face averages’ have been shown to improve recognition of famous faces, perhaps suggesting that a process akin to averaging refines mental representations of faces as they become familiar (Burton et al., 2005).
Averaging multiple images of a face in this way has also been tested as an alternative to traditional photo-ID. In a series of computer-based studies conducted by White and colleagues (2014b), participants matched images of unfamiliar faces either to single photographs or to face averages. Matching was more accurate when matching to averages, suggesting that these representations may carry practical benefits. However, in subsequent studies, the authors also found that matching accuracy was improved further by providing participants with multiple-photo arrays (similar to the images shown in the top row of Figure 3.9), suggesting that variation which is ‘washed out’ by averaging can also be informative for identification. The authors concluded that current photo-ID can be improved upon by adopting representations that are sensitive to variation across photographs of the card-bearer, instead of relying on single snapshots.
Instead of focusing on changes that can be made to the format of photo-ID, another feasible approach is to focus on training the people that check photo-ID, such as passport officers and security professionals. There is some evidence that the ability to perform face matching is relatively ‘hard-wired’, because some attempts to train this ability have produced no improvement in accuracy (e.g. Woodhead et al., 1979). However, more recently there has been some evidence that people who are initially poor at matching faces benefit from feedback training, in which they are provided with feedback on the accuracy of their responses (White et al., 2014c).
In many professions that require staff to check photo-ID and compare images of faces, people very rarely receive feedback on the accuracy of their decisions. For example, feedback in passport checking would only occur in cases where fraud was confirmed, or where fraud was mistakenly suspected. Critically, no feedback would be available in cases where fraud went undetected. As we have already discussed, rates of this type of identity fraud are extremely rare, so passport officers will rarely if ever receive feedback on the accuracy of their decisions. Providing feedback is a critical component of learning in many domains, and appears to be crucial to the development of skills, which may explain why passport officers do not become better at face matching over the course of their employment - because there is no opportunity to learn lessons from experience.
As we have discussed already, people have particular difficulty in identifying people of a different ethnicity from their own - a phenomenon known as the ‘other-race effect’ - both in memory tasks such as eyewitness identification (Meissner and Brigham, 2001) and in face-matching tasks with no memory (Megreya et al., 2011). Meissner et al. (2013) show that this also applies in tasks that closely simulate the type of face-matching decisions made by passport officers and others checking photo-ID. In their study, Mexican American participants were worse at verifying photo-ID depicting African Americans compared with Mexican Americans, and were also more confident in their incorrect judgements. One way to counteract this problem may be to train people to individuate other-race faces using computer-based training procedures (for a review see Tanaka et al., 2013); however, future testing is necessary to determine whether this type of training is able to generate improvements that transfer to real-world settings.
The development of these training methods and alternative formats for photo-ID do provide some promise that the poor levels of face identification accuracy observed across a variety of applied settings can be improved. However, the gains that have been observed so far in laboratory tests of training have been relatively small. As we will discuss in the next section, studies of human performance in face matching show that substantial gains may be available through recruitment and selection of people who are skilled in face matching.
‘SUPER-RECOGNISERS’: EXPERTISE AND INDIVIDUAL DIFFERENCES IN FACE IDENTIFICATION
In the study of passport officers described earlier in this chapter, White and colleagues (2014a) were surprised to find that passport officers made many errors on the task and were no more accurate than novice student participants. Critically, the passport officers did not appear to benefit from experience at the task. Figure 3.10 shows passport officers’ scores on the Glasgow Face Matching Test (GFMT), a standardised psycho metric test of face-matching ability (Burton et al., 2010). This reveals that there was no relationship between how long participants had been employed as a passport officer and their performance on the GFMT. However, what was also apparent was that some passport officers were extremely good at the task, achieving 100 per cent accuracy on the test, while others scored around 50 per cent (which is the accuracy you would expect if they had been guessing!). So, what if this passport office were only to employ people that score well on the GFMT? Would they be better able to detect fraudulent passport applications?
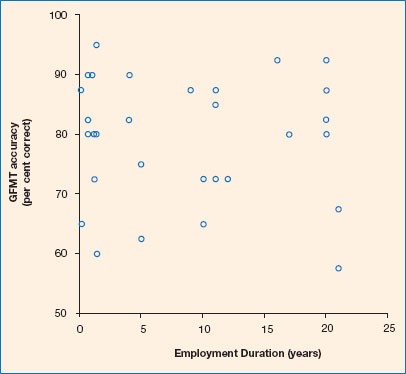
Figure 3.10 Passport officers’ performance in the Glasgow Face Matching Test.
Source: reproduced from White et al. (2014a) under a Creative Commons licence. Copyright © 2014 White et al.
For a recruitment-based solution to the passport problem to be successful, it is necessary that performance on these tasks is stable. A stable ability would be indicated by a correlation between test performance in an initial face-matching test and performance on another face-matching test performed some time later. This measure is known as ‘test-retest reliability’ and empirical tests suggest that face matching meets this criterion of stability. For example, Megreya and Burton (2007) show that the correlation between lineup matching on one portion of a test correlates highly (>0.8) with performance on another set of test items, suggesting that it might be possible to recruit individuals that have a specific skill in face identification.
More recently, Russell et al. (2009) tested individuals who claimed to have exceptional ability to recognise faces. They dubbed these people ‘Super-recognisers’ and tested their claims of super powers using a battery of tests designed to probe their face identification abilities. The intuitions of these self-proclaimed prodigies turned out to be correct - they made only a handful of errors on difficult tests of face memory and recognition, and were far better than control participants (between two and three standard deviations above mean accuracy). These individuals contrast with people at the other end of this spectrum of performance, who have specific difficulties recognising familiar faces. Awareness of this condition, known as congenital prosopagnosia or ‘face blindness’, has grown over recent years and, as a result, a large number of people have now been tested and verified as having specific impairment in face identification ability that is not related to traumatic brain injury (for a review see Susilo and Duchaine, 2013).
Researchers are currently investigating what causes this specific impairment in recognising faces. Although the causes are complicated and not fully understood, recent evidence from a twin study by Wilmer et al. (2010) strongly suggests that our ability at face recognition is to a large extent determined by our genes. In this study, test scores on a standardised test of face memory were highly correlated for identical twins but not for non-identical twins. This is further evidence that the ability to identify faces is ‘hard-wired’ - perhaps coded in our DNA - and so the selection of high performers for specialist roles would provide immediate improvements in the accuracy of face identification.
This is also a very important question from a legal perspective. As we discussed in the previous section, identification evidence in court is often provided in court by eyewitnesses. Interestingly, studies have shown that tests of face-matching ability are predictive of errors in eyewitness identification (Charles Morgan et al., 2007; Bindemann et al., 2012). People with high scores on face identification tests in these studies were less likely to make errors when identifying faces from lineups, suggesting that these tests could potentially be used to screen eyewitnesses. If judges and juries were aware of a person’s ability in face identification tasks, they might be able to weight their identification evidence appropriately.
Should variation in a witness’s natural ability to identify faces factor into the presentation of eyewitness identifications in court? This question has been raised recently in relation to a study that tested a group of ‘super-recognisers’ from the Metropolitan Police Force in London (Davis et al., 2013). These police officers appear to have superior ability in both face-matching and face-memory tasks, and this had been verified in recent tests. However, results indicate that their performance in these tests is far from perfect. Perhaps part of the reason that their performance in face identification is revered in police circles is because these super-recognisers are in roles such as custody sergeant, which give them a high level of contact with repeat offenders. As we have already discussed, most people are extremely adept at recognising the faces of the people they know.
Ultimately, the clear benefits of familiarity, combined with the very large and stable individual differences in face identification ability, pose complex challenges to the legal system. Both of these factors will have a large effect on the reliability of identification evidence when it is presented in court, but it is difficult to know how best to assess the value of the evidence. In the adversarial justice systems common to the UK, US, Australia, Canada and many other countries, judges decide whether evidence is admissible and can give special instructions to jurors relating to the reliability of the evidence. How should judges test the suitability of identification evidence? We discuss this further in the next section.
THE CCTV PROBLEM: FACIAL MAPPING AND FACIAL FORENSIC COMPARISON
Closed circuit television (CCTV) cameras are a very common sight in our city streets. In fact, as of 2011, it was estimated that in the United Kingdom there is one CCTV camera for every eleven citizens, making the UK the most monitored country in the world. Video surveillance holds the promise of deterring people from committing crime in plain sight, making city streets safer places for law-abiding citizens (Figure 3.11). Further, when crime does occur, eyewitnesses are not relied on as heavily, because image evidence is often available from these CCTV systems. Importantly, the research summarised in the previous sections shows that CCTV does not solve the problem: identification accuracy in unfamiliar face-matching tasks that do not involve memory is poor, and as a result it is not a trivial matter to identify someone from even a good-quality CCTV image.
In 2009, Davis and Valentine tested the accuracy of matching faces to CCTV footage. The authors simulated a courtroom situation by showing participants 30-second CCTV clips of young males while the ‘defendant’ sat across from them. Despite the person being present in the room, and the CCTV footage being captured only three weeks earlier, participants made over 20 per cent errors and were highly confident in 30 per cent of these erroneous decisions. This is consistent with an earlier study where police officers and students were both highly error prone when matching CCTV footage to high-quality mugshot-style images (Burton et al., 1999).

Figure 3.11 City streets are monitored by CCTV. Does this solve the problem of identifying criminal suspects?
Source: copyright Dmitry Kalinovsky / Shutterstock.com.
The Davis and Valentine (2009) study suggests that CCTV does not solve problems associated with face identification in the courtroom. However, the increased use of CCTV, combined with the growth of camera-phone use in the general population, means that digital evidence is becoming increasingly important in criminal trials. This leads to the problem of how to use this information, given how error prone we know unfamiliar face matching to be. The current approach in many jurisdictions is for the court to allow ‘expert witnesses’ to provide their opinion on the identity of the person shown in the images. Expert witnesses might be drawn from a variety of domains, such as fingerprint examiners, forensic pathologists and ballistics experts and, more recently, identification from images of people. One issue here is that the training required to perform face identification is less clear than in these other domains and, as a result, facial identification experts cite a variety of qualifications that make them suitable, such as mathematics, anatomy and anthropology. This makes it difficult for the court to establish how the expertise bears on the face-matching decision and thus the true value of the expert evidence (see Edmond et al., 2014).
The technique commonly used by these expert ‘facial mappers’ to provide identification evidence in court is known as photo-anthropometry, and is based on measuring the distances between anatomical landmarks from photographs. This technique faces a number of significant challenges a priori. First, the facial mapper must estimate the true dimensions of the face - a 3-D structure - from a 2-D image, which shows the face at a particular angle and distance from the camera. The appearance of the image will be affected by expression, head angle and other variations in the face, but also by properties of the camera lens, the lighting conditions and distance from camera. Second, even ifthe estimates were an accurate reflection of the actual dimensions of the face, it is unclear what this tells us about identity as we don’t have a database of facial dimensions across the population. As a result, we don’t know how common any particular set of facial dimensions are in the population from which the suspect was drawn.
This is important, because identification evidence should provide an estimate of the extent to which the measurements identify the person. Without an accurate estimate of the likelihood that a facial measurement would, by chance, also match a measurement taken from someone else’s face, it is not possible to ascertain the value of the identification. However, as is clear from Figure 3.12, measurements taken from faces vary across different images of the same face, often more than they vary between faces. The people pictured in Figure 3.12 are clearly different people and yet facial measurements are not able to discriminate between David Cameron and Barack Obama! It is therefore surprising that evidence based on these types of measurements continues to be permitted as evidence in criminal trials.
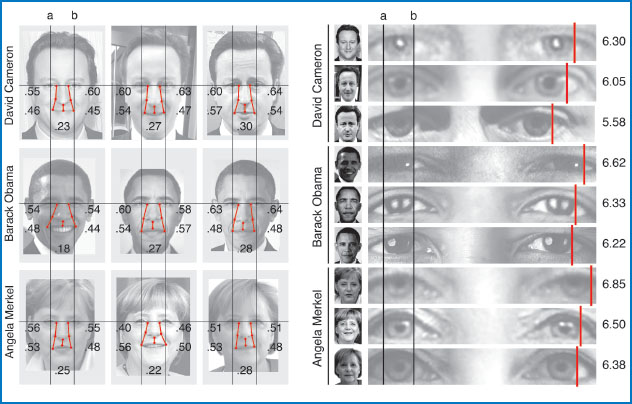
Figure 3.12 Measurements taken from three ‘heads of state’. Before making measurements, images were standardised by normalising the distance between the eyes (a to b; left panel) and the width of the iris (a to b; right panel).
Source: reproduced from Burton et al. (2015) by permission of SAGE Publications.
In addition to a priori challenges, empirical studies have also shown that facial mapping is an unreliable method of identification. For example, Kleinberg and colleagues (2007) tested the extent to which measurements taken from target faces could be used to reliably select the matching identity in an array. The researchers used the one-to-ten matching arrays from Bruce et al. (1999) and made measurements between four key landmarks (the eyes, bridge of nose and mouth), both by computing relative distances between these features and also by comparing the angles between landmarks. Neither method was useful for identification. In fact, the accuracy of this method was only slightly above the identification performance that would be expected by randomly selecting a matching face!
The evidence in support of the use of facial mapping as a reliable method for forensic identification is very weak. So, should face identification experts be admitted to give evidence in court? To answer this, it is first important to note that not all forensic identification is based on facial mapping, and some forensic facial examiners do not endorse these methods. Regardless, it is necessary to know whether these ‘experts’ are in fact more accurate at identifying faces than the population at large - whom we know are very poor at the task. There has been some recent research that has tested performance in groups of forensic examiners (e.g. Norell et al., 2015; White et al., 2015), and it appears that their performance is somewhat better than untrained student participants. However, these examiners continue to make errors on the task. Until we have sufficient evidence relating to the accuracy of forensic facial examination, it will be very difficult for judges and juries to give appropriate weight to identification evidence. This is a contentious issue and it will be interesting to see how our growing knowledge of the psychology of face recognition is applied in this field in coming years.
3.5 FACE IDENTIFICATION IN MODERN SOCIETY
We live in a globalised world where advances in technology have caused a number of important changes in methods for face identification in forensic investigation, criminal trials and national security. Some of these methods have been covered in this chapter, for example methods for extracting facial likenesses from memory. Others are more common-place in our modern society: almost everyone has a mobile phone that is able to capture images that are often ‘tagged’ by friends on Facebook; surveillance cameras are increasingly prevalent, and able to capture high-resolution imagery. This has led to digital-image evidence being especially important in forensic investigation, and in security surveillance application.
The vast scale of image data generated in modern society causes a problem of how to cope with this information for the purpose of identification. Computer engineers have aimed to solve the issue by designing pattern-matching algorithms that are able to recognise faces automatically. Accuracy of face recognition software has improved markedly over the past decade and, as a result, the performance of computers is superior to average human performance on the task (Phillips and O’Toole, 2014). This has led to wide deployment, and face recognition software is now used for various applied purposes; for example, by law enforcement during criminal investigations, and by passport issuance agencies when checking for identity fraud in the application process (see Jain et al., 2012). It is important to note, however, that these systems do not work perfectly, especially when images are of poor quality, as in most surveillance applications. As a result, the algorithms do not replace human processing, but are instead used to supplement identity verification processes. In fact, when systems such as these are used to search large databases of images - for example when police use CCTV imagery to search mugshot databases - the use of automatic face recognition software can actually increase the need for human processing.
So why would automatic face recognition software increase the need for human processing of unfamiliar faces? This paradoxical situation arises because the software used in forensic investigation provides only a ranking of the most similar-looking faces in the database. When a police officer queries the system with a ‘probe’ image (perhaps captured from a mobile image-capture device or CCTV), the software returns a ‘gallery’ of possible matches. It then falls to the human operator of the software to decide if any of the faces in the gallery match the probe image. Interestingly, this task is very similar to the one-to-many array-matching task first introduced by Bruce and colleagues (1999; see Box 3.3). The need for humans to process the output of face recognition software raises the all-too-familiar problem that humans are very poor at this task.
Automatic face recognition offers the potential to search a large database of images very quickly, generating leads in criminal investigations that may otherwise be missed. However, this also creates the problem that many of these new leads may turn out to be false leads, wasting police time and, more seriously, leading to wrongful convictions of innocent people. Forensic applications of face recognition software produce many false positives in the gallery arrays (Jain et al., 2012) and, as we know from experiments reported in this chapter, humans also make false-positive identification errors. Given this situation there is a danger that, unless we exercise caution, these new tools will become the source of the next generation of wrongful convictions that will be detected by future innocence projects.
SUMMARY
✵ Eyewitness identification evidence provided by an honest witness can be sincere, confident, convincing - and wrong!
✵ Psychologists have researched the effects of estimator and system variables on eyewitness performance and this has led to important changes in public policy.
✵ Facial composite systems that are used to re-create faces from memory have improved as a result of psychological research.
✵ The difficulty of identifying unfamiliar faces is not limited to tasks that involve memory: even when matching images of faces taken on the same day, accuracy is very poor.
✵ Face-matching accuracy is no better in people who perform face matching in their daily work (e.g. passport officers) compared with untrained students, suggesting that experience isn’t sufficient to improve accuracy.
✵ Large individual differences in unfamiliar face matching mean that some people are naturally good at the task.
✵ Methods commonly used to identify faces from photographs in the courtroom, such as ‘facial mapping’, may be unreliable.
FURTHER READING
✵ Bruce, V. and Young, A.W. (2012). Face perception. Hove: Psychology Press. Written by two of the doyens of face perception research, the publication of this book marked more than 25 years of scientific endeavour since they published the famous and still widely cited ‘Bruce and Young’ model of face recognition (Bruce and Young, 1986).
✵ Calder, A., Rhodes, G., Johnson, M. and Haxby, J. (eds). (2011). Oxford handbook of face perception. Oxford: Oxford University Press. This is an excellent collection of chapters by many of the leading researchers in the field and covers many topics we did not have space to discuss in this chapter.
✵ Hole, G. and Bourne, V. (2010). Face processing: Psychological, neuropsychological, and applied perspectives. Oxford: Oxford University Press. Another excellent review of recent research in the field, which includes a section on applied aspects of face perception.
AUTHOR NOTES
Correct answers to the face-matching tasks in this chapter are as follows:
✵ In Figure 3.1 the order of identities A and B in the photo array from left to right and top to bottom is: ABAAABABAB AAAAABBBAB BBBAAABBAA BABAABBBBB.
✵ In Figure 3.5 the matching identity is number 2.
✵ In Figure 3.8 image pair A is different people and image pair B is the same person.
FIGURE 3.9 PHOTO CREDITS
The five images of Hugh Jackman (HJ) and Gwyneth Paltrow (GP) were selected from a Google Image search by Robertson et al. using the ‘User Rights’ filter set at ‘Free to reuse’. Each of the images was labelled with a CC BY-SA 2.0 Generic or a CC BY-SA 3.0 Unported Creative Commons licence. Individual licence and attribution is outlined below.
HJ Image 1: Hugh Jackman in 2012, Photographs by Eva Rinaldi. Licence: CC BY-SA 2.0. Generic. Downloaded from: http://ro.wikipedia.org/wiki/Hugh_Jackman#mediaviewer/Fi%C8%99ier:Hugh_Jackman_4,_2012.jpg
HJ Image 2: Hugh Jackman Apr 09b, uploaded by Gryffindor to Wikipedia April 27th 2009. Licence: CC BY-SA 3.0 Unported. Downloaded from: http://en.wikipedia.org/wiki/Hugh_Jackman#mediaviewer/File:HughJackmanApr09b.jpg _
HJ Image 3: Hugh Jackman in 2012, Photographs by Eva Rinaldi. Licence: CC BY-SA 2.0 Generic. Downloaded from: http://commons.wikimedia.org/wiki/File:Hugh_Jackman_-_Flickr_-_Eva_Rinaldi_Celebrity_and_Live_Music_Photographer_(4).jpg#filelinks
HJ Image 4: HughJackmanByPaulCush2011, Photographs by Paul Cush. Licence: CC BY-SA 3.0 Unported. Downloaded from: http://fr.wikipedia.org/wiki/Hugh_Jackman#mediaviewer/Fichier:HughJackmanByPaulCush2011.jpg
HJ Image 5: Hugh Jackman by Gage Skidmore, Photographs by Gage Skidmore. Licence: CC BY-SA 3.0 Unported. Downloaded from: http://de.wikipedia.org/wiki/Hugh_Jackman#mediaviewer/Datei:Hugh_Jackman_by_Gage_Skidmore.jpg
GP Image 1: Gwyneth Paltrow at the Hollywood Walk of Fame ceremony, photograph by Richard Yaussi. Licence: CC BY-SA 2.0 Generic. Downloaded from: http://commons.wikimedia.org/wiki/File:Gwyneth_Paltrow_at_the_Hollywood_Walk_of_Fame_ceremony_-_20101213.jpg
GP Image 2: Gwyneth Paltrow 2010 by Romina Espinosa. Licence: CC BY-SA 3.0 Unported. Downloaded from: http://commons.wikimedia.org/wiki/File:Gwyneth_Paltrow_2010.jpg
GP Image 3: Gwyneth Paltrow Iron Man 3 avp Paris, Images by Georges Biard. Licence: CC BY-SA 3.0 Unported. Downloaded from: http://creativecommons.org/licenses/by-sa/3.0/
GP Image 4: Face of actress Gwyneth Paltrow, Author Jared Purdy. Licence: CC BY-SA 3.0 Unported. Downloaded from: http://commons.wikimedia.org/wiki/File:Gwyneth_Paltrow_face.jpg
GP Image 5: Gwyneth Paltrow By Andrea Raffin 2011, uploaded to Wikipedia by Electroguv on September 1st 2011. Licence: CC BY-SA 3.0 Unported. Downloaded from: http://en.wikipedia.org/wiki/Gwyneth_Paltrow#mediaviewer/File:GwynethPaltrowByAndreaRaffin2011.jpg