Superintelligence: Paths, Dangers, Strategies - Nick Bostrom (2014)
Chapter 2. Paths to superintelligence
Machines are currently far inferior to humans in general intelligence. Yet one day (we have suggested) they will be superintelligent. How do we get from here to there? This chapter explores several conceivable technological paths. We look at artificial intelligence, whole brain emulation, biological cognition, and human-machine interfaces, as well as networks and organizations. We evaluate their different degrees of plausibility as pathways to superintelligence. The existence of multiple paths increases the probability that the destination can be reached via at least one of them.
We can tentatively define a superintelligence as any intellect that greatly exceeds the cognitive performance of humans in virtually all domains of interest.1 We will have more to say about the concept of superintelligence in the next chapter, where we will subject it to a kind of spectral analysis to distinguish some different possible forms of superintelligence. But for now, the rough characterization just given will suffice. Note that the definition is noncommittal about how the superintelligence is implemented. It is also noncommittal regarding qualia: whether a superintelligence would have subjective conscious experience might matter greatly for some questions (in particular for some moral questions), but our primary focus here is on the causal antecedents and consequences of superintelligence, not on the metaphysics of mind.2
The chess program Deep Fritz is not a superintelligence on this definition, since Fritz is only smart within the narrow domain of chess. Certain kinds of domain-specific superintelligence could, however, be important. When referring to superintelligent performance limited to a particular domain, we will note the restriction explicitly. For instance, an “engineering superintelligence” would be an intellect that vastly outperforms the best current human minds in the domain of engineering. Unless otherwise noted, we use the term to refer to systems that have a superhuman level of general intelligence.
But how might we create superintelligence? Let us examine some possible paths.
Artificial intelligence
Readers of this chapter must not expect a blueprint for programming an artificial general intelligence. No such blueprint exists yet, of course. And had I been in possession of such a blueprint, I most certainly would not have published it in a book. (If the reasons for this are not immediately obvious, the arguments in subsequent chapters will make them clear.)
We can, however, discern some general features of the kind of system that would be required. It now seems clear that a capacity to learn would be an integral feature of the core design of a system intended to attain general intelligence, not something to be tacked on later as an extension or an afterthought. The same holds for the ability to deal effectively with uncertainty and probabilistic information. Some faculty for extracting useful concepts from sensory data and internal states, and for leveraging acquired concepts into flexible combinatorial representations for use in logical and intuitive reasoning, also likely belong among the core design features in a modern AI intended to attain general intelligence.
The early Good Old-Fashioned Artificial Intelligence systems did not, for the most part, focus on learning, uncertainty, or concept formation, perhaps because techniques for dealing with these dimensions were poorly developed at the time. This is not to say that the underlying ideas are all that novel. The idea of using learning as a means of bootstrapping a simpler system to human-level intelligence can be traced back at least to Alan Turing’s notion of a “child machine,” which he wrote about in 1950:
Instead of trying to produce a programme to simulate the adult mind, why not rather try to produce one which simulates the child’s? If this were then subjected to an appropriate course of education one would obtain the adult brain.3
Turing envisaged an iterative process to develop such a child machine:
We cannot expect to find a good child machine at the first attempt. One must experiment with teaching one such machine and see how well it learns. One can then try another and see if it is better or worse. There is an obvious connection between this process and evolution…. One may hope, however, that this process will be more expeditious than evolution. The survival of the fittest is a slow method for measuring advantages. The experimenter, by the exercise of intelligence, should be able to speed it up. Equally important is the fact that he is not restricted to random mutations. If he can trace a cause for some weakness he can probably think of the kind of mutation which will improve it.4
We know that blind evolutionary processes can produce human-level general intelligence, since they have already done so at least once. Evolutionary processes with foresight—that is, genetic programs designed and guided by an intelligent human programmer—should be able to achieve a similar outcome with far greater efficiency. This observation has been used by some philosophers and scientists, including David Chalmers and Hans Moravec, to argue that human-level AI is not only theoretically possible but feasible within this century.5 The idea is that we can estimate the relative capabilities of evolution and human engineering to produce intelligence, and find that human engineering is already vastly superior to evolution in some areas and is likely to become superior in the remaining areas before too long. The fact that evolution produced intelligence therefore indicates that human engineering will soon be able to do the same. Thus, Moravec wrote (already back in 1976):
The existence of several examples of intelligence designed under these constraints should give us great confidence that we can achieve the same in short order. The situation is analogous to the history of heavier than air flight, where birds, bats and insects clearly demonstrated the possibility before our culture mastered it.6
One needs to be cautious, though, in what inferences one draws from this line of reasoning. It is true that evolution produced heavier-than-air flight, and that human engineers subsequently succeeded in doing likewise (albeit by means of a very different mechanism). Other examples could also be adduced, such as sonar, magnetic navigation, chemical weapons, photoreceptors, and all kinds of mechanic and kinetic performance characteristics. However, one could equally point to areas where human engineers have thus far failed to match evolution: in morphogenesis, self-repair, and the immune defense, for example, human efforts lag far behind what nature has accomplished. Moravec’s argument, therefore, cannot give us “great confidence” that we can achieve human-level artificial intelligence “in short order.” At best, the evolution of intelligent life places an upper bound on the intrinsic difficulty of designing intelligence. But this upper bound could be quite far above current human engineering capabilities.
Another way of deploying an evolutionary argument for the feasibility of AI is via the idea that we could, by running genetic algorithms on sufficiently fast computers, achieve results comparable to those of biological evolution. This version of the evolutionary argument thus proposes a specific method whereby intelligence could be produced.
But is it true that we will soon have computing power sufficient to recapitulate the relevant evolutionary processes that produced human intelligence? The answer depends both on how much computing technology will advance over the next decades and on how much computing power would be required to run genetic algorithms with the same optimization power as the evolutionary process of natural selection that lies in our past. Although, in the end, the conclusion we get from pursuing this line of reasoning is disappointingly indeterminate, it is instructive to attempt a rough estimate (see Box 3). If nothing else, the exercise draws attention to some interesting unknowns.
The upshot is that the computational resources required to simply replicate the relevant evolutionary processes on Earth that produced human-level intelligence are severely out of reach—and will remain so even if Moore’s law were to continue for a century (cf. Figure 3). It is plausible, however, that compared with brute-force replication of natural evolutionary processes, vast efficiency gains are achievable by designing the search process to aim for intelligence, using various obvious improvements over natural selection. Yet it is very hard to bound the magnitude of those attainable efficiency gains. We cannot even say whether they amount to five or to twenty-five orders of magnitude. Absent further elaboration, therefore, evolutionary arguments are not able to meaningfully constrain our expectations of either the difficulty of building human-level machine intelligence or the timescales for such developments.
Box 3 What would it take to recapitulate evolution?
Not every feat accomplished by evolution in the course of the development of human intelligence is relevant to a human engineer trying to artificially evolve machine intelligence. Only a small portion of evolutionary selection on Earth has been selection for intelligence. More specifically, the problems that human engineers cannot trivially bypass may have been the target of a very small portion of total evolutionary selection. For example, since we can run our computers on electrical power, we do not have to reinvent the molecules of the cellular energy economy in order to create intelligent machines—yet such molecular evolution of metabolic pathways might have used up a large part of the total amount of selection power that was available to evolution over the course of Earth’s history.7
One might argue that the key insights for AI are embodied in the structure of nervous systems, which came into existence less than a billion years ago.8 If we take that view, then the number of relevant “experiments” available to evolution is drastically curtailed. There are some 4-6×1030 prokaryotes in the world today, but only 1019 insects, and fewer than 1010 humans (while pre-agricultural populations were orders of magnitude smaller).9 These numbers are only moderately intimidating.
Evolutionary algorithms, however, require not only variations to select among but also a fitness function to evaluate variants, and this is typically the most computationally expensive component. A fitness function for the evolution of artificial intelligence plausibly requires simulation of neural development, learning, and cognition to evaluate fitness. We might thus do better not to look at the raw number of organisms with complex nervous systems, but instead to attend to the number of neurons in biological organisms that we might need to simulate to mimic evolution’s fitness function. We can make a crude estimate of that latter quantity by considering insects, which dominate terrestrial animal biomass (with ants alone estimated to contribute some 15-20%).10 Insect brain size varies substantially, with large and social insects sporting larger brains: a honeybee brain has just under 106 neurons, a fruit fly brain has 105 neurons, and ants are in between with 250,000 neurons.11 The majority of smaller insects may have brains of only a few thousand neurons. Erring on the side of conservatively high, if we assigned all 1019 insects fruit-fly numbers of neurons, the total would be 1024 insect neurons in the world. This could be augmented with an additional order of magnitude to account for aquatic copepods, birds, reptiles, mammals, etc., to reach 1025. (By contrast, in pre-agricultural times there were fewer than 107 humans, with under 1011 neurons each: thus fewer than 1018 human neurons in total, though humans have a higher number of synapses per neuron.)
The computational cost of simulating one neuron depends on the level of detail that one includes in the simulation. Extremely simple neuron models use about 1,000 floating-point operations per second (FLOPS) to simulate one neuron (in real-time). The electrophysiologically realistic Hodgkin-Huxley model uses 1,200,000 FLOPS. A more detailed multi-compartmental model would add another three to four orders of magnitude, while higher-level models that abstract systems of neurons could subtract two to three orders of magnitude from the simple models.12 If we were to simulate 1025 neurons over a billion years of evolution (longer than the existence of nervous systems as we know them), and we allow our computers to run for one year, these figures would give us a requirement in the range of 1031-1044 FLOPS. For comparison, China’s Tianhe-2, the world’s most powerful supercomputer as of September 2013, provides only 3.39×1016 FLOPS. In recent decades, it has taken approximately 6.7 years for commodity computers to increase in power by one order of magnitude. Even a century of continued Moore’s law would not be enough to close this gap. Running more specialized hardware, or allowing longer run-times, could contribute only a few more orders of magnitude.
This figure is conservative in another respect. Evolution achieved human intelligence without aiming at this outcome. In other words, the fitness functions for natural organisms do not select only for intelligence and its precursors.13 Even environments in which organisms with superior information processing skills reap various rewards may not select for intelligence, because improvements to intelligence can (and often do) impose significant costs, such as higher energy consumption or slower maturation times, and those costs may outweigh whatever benefits are gained from smarter behavior. Excessively deadly environments also reduce the value of intelligence: the shorter one’s expected lifespan, the less time there will be for increased learning ability to pay off. Reduced selective pressure for intelligence slows the spread of intelligence-enhancing innovations, and thus the opportunity for selection to favor subsequent innovations that depend on them. Furthermore, evolution may wind up stuck in local optima that humans would notice and bypass by altering tradeoffs between exploitation and exploration or by providing a smooth progression of increasingly difficult intelligence tests.14 And as mentioned earlier, evolution scatters much of its selection power on traits that are unrelated to intelligence (such as Red Queen’s races of competitive co-evolution between immune systems and parasites). Evolution continues to waste resources producing mutations that have proved consistently lethal, and it fails to take advantage of statistical similarities in the effects of different mutations. These are all inefficiencies in natural selection (when viewed as a means of evolving intelligence) that it would be relatively easy for a human engineer to avoid while using evolutionary algorithms to develop intelligent software.
It is plausible that eliminating inefficiencies like those just described would trim many orders of magnitude off the 1031-1044 FLOPS range calculated earlier. Unfortunately, it is difficult to know how many orders of magnitude. It is difficult even to make a rough estimate—for aught we know, the efficiency savings could be five orders of magnitude, or ten, or twenty-five.15
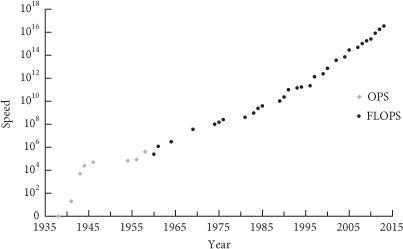
Figure 3 Supercomputer performance. In a narrow sense, “Moore’s law” refers to the observation that the number of transistors on integrated circuits have for several decades doubled approximately every two years. However, the term is often used to refer to the more general observation that many performance metrics in computing technology have followed a similarly fast exponential trend. Here we plot peak speed of the world’s fastest supercomputer as a function of time (on a logarithmic vertical scale). In recent years, growth in the serial speed of processors has stagnated, but increased use of parallelization has enabled the total number of computations performed to remain on the trend line.16
There is a further complication with these kinds of evolutionary considerations, one that makes it hard to derive from them even a very loose upper bound on the difficulty of evolving intelligence. We must avoid the error of inferring, from the fact that intelligent life evolved on Earth, that the evolutionary processes involved had a reasonably high prior probability of producing intelligence. Such an inference is unsound because it fails to take account of the observation selection effect that guarantees that all observers will find themselves having originated on a planet where intelligent life arose, no matter how likely or unlikely it was for any given such planet to produce intelligence. Suppose, for example, that in addition to the systematic effects of natural selection it required an enormous amount of lucky coincidence to produce intelligent life—enough so that intelligent life evolves on only one planet out of every 1030 planets on which simple replicators arise. In that case, when we run our genetic algorithms to try to replicate what natural evolution did, we might find that we must run some 1030 simulations before we find one where all the elements come together in just the right way. This seems fully consistent with our observation that life did evolve here on Earth. Only by careful and somewhat intricate reasoning—by analyzing instances of convergent evolution of intelligence-related traits and engaging with the subtleties of observation selection theory—can we partially circumvent this epistemological barrier. Unless one takes the trouble to do so, one is not in a position to rule out the possibility that the alleged “upper bound” on the computational requirements for recapitulating the evolution of intelligence derived in Box 3 might be too low by thirty orders of magnitude (or some other such large number).17
Another way of arguing for the feasibility of artificial intelligence is by pointing to the human brain and suggesting that we could use it as a template for a machine intelligence. One can distinguish different versions of this approach based on how closely they propose to imitate biological brain functions. At one extreme—that of very close imitation—we have the idea of whole brain emulation, which we will discuss in the next subsection. At the other extreme are approaches that take their inspiration from the functioning of the brain but do not attempt low-level imitation. Advances in neuroscience and cognitive psychology—which will be aided by improvements in instrumentation—should eventually uncover the general principles of brain function. This knowledge could then guide AI efforts. We have already encountered neural networks as an example of a brain-inspired AI technique. Hierarchical perceptual organization is another idea that has been transferred from brain science to machine learning. The study of reinforcement learning has been motivated (at least in part) by its role in psychological theories of animal cognition, and reinforcement learning techniques (e.g. the “TD-algorithm”) inspired by these theories are now widely used in AI.18 More cases like these will surely accumulate in the future. Since there is a limited number—perhaps a very small number—of distinct fundamental mechanisms that operate in the brain, continuing incremental progress in brain science should eventually discover them all. Before this happens, though, it is possible that a hybrid approach, combining some brain-inspired techniques with some purely artificial methods, would cross the finishing line. In that case, the resultant system need not be recognizably brain-like even though some brain-derived insights were used in its development.
The availability of the brain as template provides strong support for the claim that machine intelligence is ultimately feasible. This, however, does not enable us to predict when it will be achieved because it is hard to predict the future rate of discoveries in brain science. What we can say is that the further into the future we look, the greater the likelihood that the secrets of the brain’s functionality will have been decoded sufficiently to enable the creation of machine intelligence in this manner.
Different people working toward machine intelligence hold different views about how promising neuromorphic approaches are compared with approaches that aim for completely synthetic designs. The existence of birds demonstrated that heavier-than-air flight was physically possible and prompted efforts to build flying machines. Yet the first functioning airplanes did not flap their wings. The jury is out on whether machine intelligence will be like flight, which humans achieved through an artificial mechanism, or like combustion, which we initially mastered by copying naturally occurring fires.
Turing’s idea of designing a program that acquires most of its content by learning, rather than having it pre-programmed at the outset, can apply equally to neuromorphic and synthetic approaches to machine intelligence.
A variation on Turing’s conception of a child machine is the idea of a “seed AI.”19 Whereas a child machine, as Turing seems to have envisaged it, would have a relatively fixed architecture that simply develops its inherent potentialities by accumulating content, a seed AI would be a more sophisticated artificial intelligence capable of improving its own architecture. In the early stages of a seed AI, such improvements might occur mainly through trial and error, information acquisition, or assistance from the programmers. At its later stages, however, a seed AI should be able to understand its own workings sufficiently to engineer new algorithms and computational structures to bootstrap its cognitive performance. This needed understanding could result from the seed AI reaching a sufficient level of general intelligence across many domains, or from crossing some threshold in a particularly relevant domain such as computer science or mathematics.
This brings us to another important concept, that of “recursive self-improvement.” A successful seed AI would be able to iteratively enhance itself: an early version of the AI could design an improved version of itself, and the improved version—being smarter than the original—might be able to design an even smarter version of itself, and so forth.20 Under some conditions, such a process of recursive self-improvement might continue long enough to result in an intelligence explosion—an event in which, in a short period of time, a system’s level of intelligence increases from a relatively modest endowment of cognitive capabilities (perhaps sub-human in most respects, but with a domain-specific talent for coding and AI research) to radical superintelligence. We will return to this important possibility in Chapter 4, where the dynamics of such an event will be analyzed more closely. Note that this model suggests the possibility of surprises: attempts to build artificial general intelligence might fail pretty much completely until the last missing critical component is put in place, at which point a seed AI might become capable of sustained recursive self-improvement.
Before we end this subsection, there is one more thing that we should emphasize, which is that an artificial intelligence need not much resemble a human mind. AIs could be—indeed, it is likely that most will be—extremely alien. We should expect that they will have very different cognitive architectures than biological intelligences, and in their early stages of development they will have very different profiles of cognitive strengths and weaknesses (though, as we shall later argue, they could eventually overcome any initial weakness). Furthermore, the goal systems of AIs could diverge radically from those of human beings. There is no reason to expect a generic AI to be motivated by love or hate or pride or other such common human sentiments: these complex adaptations would require deliberate expensive effort to recreate in AIs. This is at once a big problem and a big opportunity. We will return to the issue of AI motivation in later chapters, but it is so central to the argument in this book that it is worth bearing in mind throughout.
Whole brain emulation
In whole brain emulation (also known as “uploading”), intelligent software would be produced by scanning and closely modeling the computational structure of a biological brain. This approach thus represents a limiting case of drawing inspiration from nature: barefaced plagiarism. Achieving whole brain emulation requires the accomplishment of the following steps.
First, a sufficiently detailed scan of a particular human brain is created. This might involve stabilizing the brain post-mortem through vitrification (a process that turns tissue into a kind of glass). A machine could then dissect the tissue into thin slices, which could be fed into another machine for scanning, perhaps by an array of electron microscopes. Various stains might be applied at this stage to bring out different structural and chemical properties. Many scanning machines could work in parallel to process multiple brain slices simultaneously.
Second, the raw data from the scanners is fed to a computer for automated image processing to reconstruct the three-dimensional neuronal network that implemented cognition in the original brain. In practice, this step might proceed concurrently with the first step to reduce the amount of high-resolution image data stored in buffers. The resulting map is then combined with a library of neurocomputational models of different types of neurons or of different neuronal elements (such as particular kinds of synaptic connectors). Figure 4 shows some results of scanning and image processing produced with present-day technology.
In the third stage, the neurocomputational structure resulting from the previous step is implemented on a sufficiently powerful computer. If completely successful, the result would be a digital reproduction of the original intellect, with memory and personality intact. The emulated human mind now exists as software on a computer. The mind can either inhabit a virtual reality or interface with the external world by means of robotic appendages.
The whole brain emulation path does not require that we figure out how human cognition works or how to program an artificial intelligence. It requires only that we understand the low-level functional characteristics of the basic computational elements of the brain. No fundamental conceptual or theoretical breakthrough is needed for whole brain emulation to succeed.
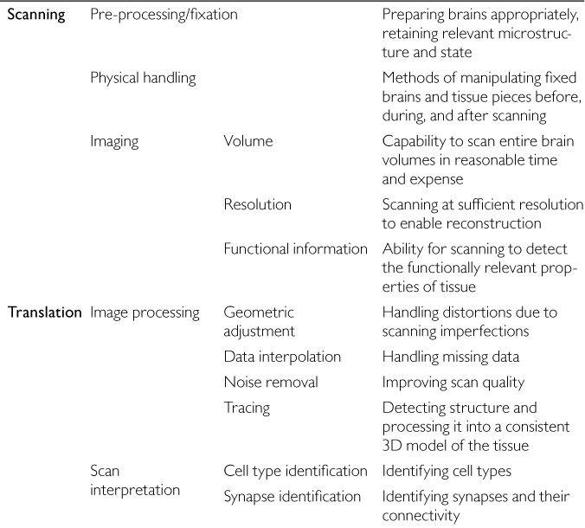
Whole brain emulation does, however, require some rather advanced enabling technologies. There are three key prerequisites: (1) scanning: high-throughput microscopy with sufficient resolution and detection of relevant properties; (2) translation: automated image analysis to turn raw scanning data into an interpreted three-dimensional model of relevant neurocomputational elements; and (3) simulation: hardware powerful enough to implement the resultant computational structure (see Table 4). (In comparison with these more challenging steps, the construction of a basic virtual reality or a robotic embodiment with an audiovisual input channel and some simple output channel is relatively easy. Simple yet minimally adequate I/O seems feasible already with present technology.23)

Figure 4 Reconstructing 3D neuroanatomy from electron microscope images. Upper left: A typical electron micrograph showing cross-sections of neuronal matter—dendrites and axons. Upper right: Volume image of rabbit retinal neural tissue acquired by serial block-face scanning electron microscopy.21 Individual 2D images have been stacked into a cube (with a side of approximately 11 μm). Bottom: Reconstruction of a subset of the neuronal projections filling a volume of neuropil, generated by an automated segmentation algorithm.22
There is good reason to think that the requisite enabling technologies are attainable, though not in the near future. Reasonable computational models of many types of neuron and neuronal processes already exist. Image recognition software has been developed that can trace axons and dendrites through a stack of two-dimensional images (though reliability needs to be improved). And there are imaging tools that provide the necessary resolution—with a scanning tunneling microscope it is possible to “see” individual atoms, which is a far higher resolution than needed. However, although present knowledge and capabilities suggest that there is no in-principle barrier to the development of the requisite enabling technologies, it is clear that a very great deal of incremental technical progress would be needed to bring human whole brain emulation within reach.24 For example, microscopy technology would need not just sufficient resolution but also sufficient throughput. Using an atomic-resolution scanning tunneling microscope to image the needed surface area would be far too slow to be practicable. It would be more plausible to use a lower-resolution electron microscope, but this would require new methods for preparing and staining cortical tissue to make visible relevant details such as synaptic fine structure. A great expansion of neurocomputational libraries and major improvements in automated image processing and scan interpretation would also be needed.
Table 4 Capabilities needed for whole brain emulation

In general, whole brain emulation relies less on theoretical insight and more on technological capability than artificial intelligence. Just how much technology is required for whole brain emulation depends on the level of abstraction at which the brain is emulated. In this regard there is a tradeoff between insight and technology. In general, the worse our scanning equipment and the feebler our computers, the less we could rely on simulating low-level chemical and electrophysiological brain processes, and the more theoretical understanding would be needed of the computational architecture that we are seeking to emulate in order to create more abstract representations of the relevant functionalities.25 Conversely, with sufficiently advanced scanning technology and abundant computing power, it might be possible to brute-force an emulation even with a fairly limited understanding of the brain. In the unrealistic limiting case, we could imagine emulating a brain at the level of its elementary particles using the quantum mechanical Schrödinger equation. Then one could rely entirely on existing knowledge of physics and not at all on any biological model. This extreme case, however, would place utterly impracticable demands on computational power and data acquisition. A far more plausible level of emulation would be one that incorporates individual neurons and their connectivity matrix, along with some of the structure of their dendritic trees and maybe some state variables of individual synapses. Neurotransmitter molecules would not be simulated individually, but their fluctuating concentrations would be modeled in a coarse-grained manner.
To assess the feasibility of whole brain emulation, one must understand the criterion for success. The aim is not to create a brain simulation so detailed and accurate that one could use it to predict exactly what would have happened in the original brain if it had been subjected to a particular sequence of stimuli. Instead, the aim is to capture enough of the computationally functional properties of the brain to enable the resultant emulation to perform intellectual work. For this purpose, much of the messy biological detail of a real brain is irrelevant.
A more elaborate analysis would distinguish between different levels of emulation success based on the extent to which the information-processing functionality of the emulated brain has been preserved. For example, one could distinguish among (1) a high-fidelity emulation that has the full set of knowledge, skills, capacities, and values of the emulated brain; (2) a distorted emulation whose dispositions are significantly non-human in some ways but which is mostly able to do the same intellectual labor as the emulated brain; and (3) a generic emulation (which might also be distorted) that is somewhat like an infant, lacking the skills or memories that had been acquired by the emulated adult brain but with the capacity to learn most of what a normal human can learn.26
While it appears ultimately feasible to produce a high-fidelity emulation, it seems quite likely that the first whole brain emulation that we would achieve if we went down this path would be of a lower grade. Before we would get things to work perfectly, we would probably get things to work imperfectly. It is also possible that a push toward emulation technology would lead to the creation of some kind of neuromorphic AI that would adapt some neurocomputational principles discovered during emulation efforts and hybridize them with synthetic methods, and that this would happen before the completion of a fully functional whole brain emulation. The possibility of such a spillover into neuromorphic AI, as we shall see in a later chapter, complicates the strategic assessment of the desirability of seeking to expedite emulation technology.
How far are we currently from achieving a human whole brain emulation? One recent assessment presented a technical roadmap and concluded that the prerequisite capabilities might be available around mid-century, though with a large uncertainty interval.27 Figure 5 depicts the major milestones in this roadmap. The apparent simplicity of the map may be deceptive, however, and we should be careful not to understate how much work remains to be done. No brain has yet been emulated. Consider the humble model organism Caenorhabditis elegans, which is a transparent roundworm, about 1 mm in length, with 302 neurons. The complete connectivity matrix of these neurons has been known since the mid-1980s, when it was laboriously mapped out by means of slicing, electron microscopy, and hand-labeling of specimens.29 But knowing merely which neurons are connected with which is not enough. To create a brain emulation one would also need to know which synapses are excitatory and which are inhibitory; the strength of the connections; and various dynamical properties of axons, synapses, and dendritic trees. This information is not yet available even for the small nervous system of C. elegans (although it may now be within range of a targeted moderately sized research project).30 Success at emulating a tiny brain, such as that of C. elegans, would give us a better view of what it would take to emulate larger brains.
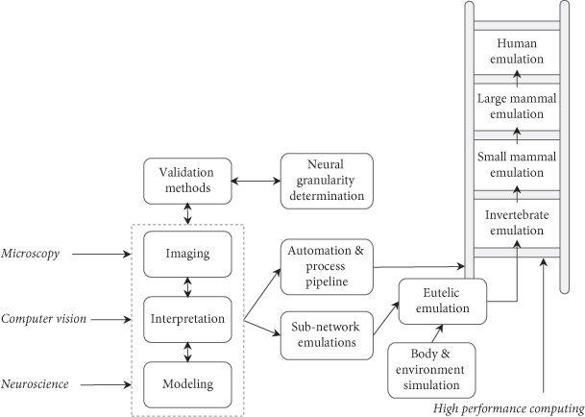
Figure 5 Whole brain emulation roadmap. Schematic of inputs, activities, and milestones.28
At some point in the technology development process, once techniques are available for automatically emulating small quantities of brain tissue, the problem reduces to one of scaling. Notice “the ladder” at the right side of Figure 5. This ascending series of boxes represents a final sequence of advances which can commence after preliminary hurdles have been cleared. The stages in this sequence correspond to whole brain emulations of successively more neurologically sophisticated model organisms—for example, C. elegans → honeybee → mouse → rhesus monkey → human. Because the gaps between these rungs—at least after the first step—are mostly quantitative in nature and due mainly (though not entirely) to the differences in size of the brains to be emulated, they should be tractable through a relatively straightforward scale-up of scanning and simulation capacity.31
Once we start ascending this final ladder, the eventual attainment of human whole brain emulation becomes more clearly foreseeable.32 We can thus expect to get some advance warning before arrival at human-level machine intelligence along the whole brain emulation path, at least if the last among the requisite enabling technologies to reach sufficient maturity is either high-throughput scanning or the computational power needed for real-time simulation. If, however, the last enabling technology to fall into place is neurocomputational modeling, then the transition from unimpressive prototypes to a working human emulation could be more abrupt. One could imagine a scenario in which, despite abundant scanning data and fast computers, it is proving difficult to get our neuronal models to work right. When finally the last glitch is ironed out, what was previously a completely dysfunctional system—analogous perhaps to an unconscious brain undergoing a grand mal seizure—might snap into a coherent wakeful state. In this case, the key advance would not be heralded by a series of functioning animal emulations of increasing magnitude (provoking newspaper headlines of correspondingly escalating font size). Even for those paying attention it might be difficult to tell in advance of success just how many flaws remained in the neurocomputational models at any point and how long it would take to fix them, even up to the eve of the critical breakthrough. (Once a human whole brain emulation has been achieved, further potentially explosive developments would take place; but we postpone discussion of this until Chapter 4.)
Surprise scenarios are thus imaginable for whole brain emulation even if all the relevant research were conducted in the open. Nevertheless, compared with the AI path to machine intelligence, whole brain emulation is more likely to be preceded by clear omens since it relies more on concrete observable technologies and is not wholly based on theoretical insight. We can also say, with greater confidence than for the AI path, that the emulation path will not succeed in the near future (within the next fifteen years, say) because we know that several challenging precursor technologies have not yet been developed. By contrast, it seems likely that somebody could in principle sit down and code a seed AI on an ordinary present-day personal computer; and it is conceivable—though unlikely—that somebody somewhere will get the right insight for how to do this in the near future.
Biological cognition
A third path to greater-than-current-human intelligence is to enhance the functioning of biological brains. In principle, this could be achieved without technology, through selective breeding. Any attempt to initiate a classical large-scale eugenics program, however, would confront major political and moral hurdles. Moreover, unless the selection were extremely strong, many generations would be required to produce substantial results. Long before such an initiative would bear fruit, advances in biotechnology will allow much more direct control of human genetics and neurobiology, rendering otiose any human breeding program. We will therefore focus on methods that hold the potential to deliver results faster, on the timescale of a few generations or less.
Our individual cognitive capacities can be strengthened in various ways, including by such traditional methods as education and training. Neurological development can be promoted by low-tech interventions such as optimizing maternal and infant nutrition, removing lead and other neurotoxic pollutants from the environment, eradicating parasites, ensuring adequate sleep and exercise, and preventing diseases that affect the brain.33 Improvements in cognition can certainly be obtained through each of these means, though the magnitudes of the gains are likely to be modest, especially in populations that are already reasonably well-nourished and -schooled. We will certainly not achieve superintelligence by any of these means, but they might help on the margin, particularly by lifting up the deprived and expanding the catchment of global talent. (Lifelong depression of intelligence due to iodine deficiency remains widespread in many impoverished inland areas of the world—an outrage given that the condition can be prevented by fortifying table salt at a cost of a few cents per person and year.34)
Biomedical enhancements could give bigger boosts. Drugs already exist that are alleged to improve memory, concentration, and mental energy in at least some subjects.35 (Work on this book was fueled by coffee and nicotine chewing gum.) While the efficacy of the present generation of smart drugs is variable, marginal, and generally dubious, future nootropics might offer clearer benefits and fewer side effects.36 However, it seems implausible, on both neurological and evolutionary grounds, that one could by introducing some chemical into the brain of a healthy person spark a dramatic rise in intelligence.37 The cognitive functioning of a human brain depends on a delicate orchestration of many factors, especially during the critical stages of embryo development—and it is much more likely that this self-organizing structure, to be enhanced, needs to be carefully balanced, tuned, and cultivated rather than simply flooded with some extraneous potion.
Manipulation of genetics will provide a more powerful set of tools than psychopharmacology. Consider again the idea of genetic selection: instead of trying to implement a eugenics program by controlling mating patterns, one could use selection at the level of embryos or gametes.38 Pre-implantation genetic diagnosis has already been used during in vitro fertilization procedures to screen embryos produced for monogenic disorders such as Huntington’s disease and for predisposition to some late-onset diseases such as breast cancer. It has also been used for sex selection and for matching human leukocyte antigen type with that of a sick sibling, who can then benefit from a cord-blood stem cell donation when the new baby is born.39 The range of traits that can be selected for or against will expand greatly over the next decade or two. A strong driver of progress in behavioral genetics is the rapidly falling cost of genotyping and gene sequencing. Genome-wide complex trait analysis, using studies with vast numbers of subjects, is just now starting to become feasible and will greatly increase our knowledge of the genetic architectures of human cognitive and behavioral traits.40 Any trait with a non-negligible heritability—including cognitive capacity—could then become susceptible to selection.41 Embryo selection does not require a deep understanding of the causal pathways by which genes, in complicated interplay with environments, produce phenotypes: it requires only (lots of) data on the genetic correlates of the traits of interest.
It is possible to calculate some rough estimates of the magnitude of the gains obtainable in different selection scenarios.42 Table 5 shows expected increases in intelligence resulting from various amounts of selection, assuming complete information about the common additive genetic variants underlying the narrow-sense heritability of intelligence. (With partial information, the effectiveness of selection would be reduced, though not quite to the extent one might naively expect.44) Unsurprisingly, selecting between larger numbers of embryos produces larger gains, but there are steeply diminishing returns: selection between 100 embryos does not produce a gain anywhere near fifty times as large as that which one would get from selection between 2 embryos.45
Table 5 Maximum IQ gains from selecting among a set of embryos43
|
Selection |
IQ points gained |
|
1 in 2 |
4.2 |
|
1 in 10 |
11.5 |
|
1 in 100 |
18.8 |
|
1 in 1000 |
24.3 |
|
5 generations of 1 in 10 |
< 65 (b/c diminishing returns) |
|
10 generations of 1 in 10 |
< 130 (b/c diminishing returns) |
|
Cumulative limits (additive variants optimized for cognition) |
100 + (< 300 (b/c diminishing returns)) |
Interestingly, the diminishment of returns is greatly abated when the selection is spread over multiple generations. Thus, repeatedly selecting the top 1 in 10 over ten generations (where each new generation consists of the offspring of those selected in the previous generation) will produce a much greater increase in the trait value than a one-off selection of 1 in 100. The problem with sequential selection, of course, is that it takes longer. If each generational step takes twenty or thirty years, then even just five successive generations would push us well into the twenty-second century. Long before then, more direct and powerful modes of genetic engineering (not to mention machine intelligence) will most likely be available.
There is, however, a complementary technology, one which, once it has been developed for use in humans, would greatly potentiate the enhancement power of pre-implantation genetic screening: namely, the derivation of viable sperm and eggs from embryonic stem cells.46 The techniques for this have already been used to produce fertile offspring in mice and gamete-like cells in humans. Substantial scientific challenges remain, however, in translating the animal results to humans and in avoiding epigenetic abnormalities in the derived stem cell lines. According to one expert, these challenges might put human application “10 or even 50 years in the future.”47
With stem cell-derived gametes, the amount of selection power available to a couple could be greatly increased. In current practice, an in vitro fertilization procedure typically involves the creation of fewer than ten embryos. With stem cell-derived gametes, a few donated cells might be turned into a virtually unlimited number of gametes that could be combined to produce embryos, which could then be genotyped or sequenced, and the most promising one chosen for implantation. Depending on the cost of preparing and screening each individual embryo, this technology could yield a severalfold increase in the selective power available to couples using in vitro fertilization.
More importantly still, stem cell-derived gametes would allow multiple generations of selection to be compressed into less than a human maturation period, by enabling iterated embryo selection. This is a procedure that would consist of the following steps:48
1 Genotype and select a number of embryos that are higher in desired genetic characteristics.
2 Extract stem cells from those embryos and convert them to sperm and ova, maturing within six months or less.49
3 Cross the new sperm and ova to produce embryos.
4 Repeat until large genetic changes have been accumulated.
In this manner, it would be possible to accomplish ten or more generations of selection in just a few years. (The procedure would be time-consuming and expensive; however, in principle, it would need to be done only once rather than repeated for each birth. The cell lines established at the end of the procedure could be used to generate very large numbers of enhanced embryos.)
As Table 5 indicates, the average level of intelligence among individuals conceived in this manner could be very high, possibly equal to or somewhat above that of the most intelligent individual in the historical human population. A world that had a large population of such individuals might (if it had the culture, education, communications infrastructure, etc., to match) constitute a collective superintelligence.
The impact of this technology will be dampened and delayed by several factors. There is the unavoidable maturational lag while the finally selected embryos grow into adult human beings: at least twenty years before an enhanced child reaches full productivity, longer still before such children come to constitute a substantial segment of the labor force. Furthermore, even after the technology has been perfected, adoption rates will probably start out low. Some countries might prohibit its use altogether, on moral or religious grounds.50 Even where selection is allowed, many couples will prefer the natural way of conceiving. Willingness to use IVF, however, would increase if there were clearer benefits associated with the procedure—such as a virtual guarantee that the child would be highly talented and free from genetic predispositions to disease. Lower health care costs and higher expected lifetime earnings would also argue in favor of genetic selection. As use of the procedure becomes more common, particularly among social elites, there might be a cultural shift toward parenting norms that present the use of selection as the thing that responsible enlightened couples do. Many of the initially reluctant might join the bandwagon in order to have a child that is not at a disadvantage relative to the enhanced children of their friends and colleagues. Some countries might offer inducements to encourage their citizens to take advantage of genetic selection in order to increase the country’s stock of human capital, or to increase long-term social stability by selecting for traits like docility, obedience, submissiveness, conformity, risk-aversion, or cowardice, outside of the ruling clan.
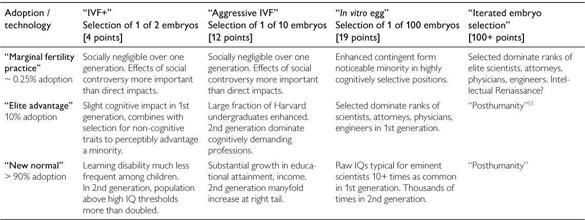
Effects on intellectual capacity would also depend on the extent to which the available selection power would be used for enhancing cognitive traits (Table 6). Those who do opt to use some form of embryo selection would have to choose how to allocate the selection power at their disposal, and intelligence would to some extent be in competition with other desired attributes, such as health, beauty, personality, or athleticism. Iterated embryo selection, by offering such a large amount of selection power, would alleviate some of these tradeoffs, enabling simultaneous strong selection for multiple traits. However, this procedure would tend to disrupt the normal genetic relationship between parents and child, something that could negatively affect demand in many cultures.51
With further advances in genetic technology, it may become possible to synthesize genomes to specification, obviating the need for large pools of embryos. DNA synthesis is already a routine and largely automated biotechnology, though it is not yet feasible to synthesize an entire human genome that could be used in a reproductive context (not least because of still-unresolved difficulties in getting the epigenetics right).54 But once this technology has matured, an embryo could be designed with the exact preferred combination of genetic inputs from each parent. Genes that are present in neither of the parents could also be spliced in, including alleles that are present with low frequency in the population but which may have significant positive effects on cognition.55
Table 6 Possible impacts from genetic selection in different scenarios52
One intervention that becomes possible when human genomes can be synthesized is genetic “spell-checking” of an embryo. (Iterated embryo selection might also allow an approximation of this.) Each of us currently carries a mutational load, with perhaps hundreds of mutations that reduce the efficiency of various cellular processes.56 Each individual mutation has an almost negligible effect (whence it is only slowly removed from the gene pool), yet in combination such mutations may exact a heavy toll on our functioning.57 Individual differences in intelligence might to a significant extent be attributable to variations in the number and nature of such slightly deleterious alleles that each of us carries. With gene synthesis we could take the genome of an embryo and construct a version of that genome free from the genetic noise of accumulated mutations. If one wished to speak provocatively, one could say that individuals created from such proofread genomes might be “more human” than anybody currently alive, in that they would be less distorted expressions of human form. Such people would not all be carbon copies, because humans vary genetically in ways other than by carrying different deleterious mutations. But the phenotypical manifestation of a proofread genome may be an exceptional physical and mental constitution, with elevated functioning in polygenic trait dimensions like intelligence, health, hardiness, and appearance.58 (A loose analogy could be made with composite faces, in which the defects of the superimposed individuals are averaged out: see Figure 6.)

Figure 6 Composite faces as a metaphor for spell-checked genomes. Each of the central pictures was produced by superimposing photographs of sixteen different individuals (residents of Tel Aviv). Composite faces are often judged to be more beautiful than any of the individual faces of which they are composed, as idiosyncratic imperfections are averaged out. Analogously, by removing individual mutations, proofread genomes may produce people closer to “Platonic ideals.” Such individuals would not all be genetically identical, because many genes come in multiple equally functional alleles. Proofreading would only eliminate variance arising from deleterious mutations.59
Other potential biotechnological techniques might also be relevant. Human reproductive cloning, once achieved, could be used to replicate the genome of exceptionally talented individuals. Uptake would be limited by the preference of most prospective parents to be biologically related to their children, yet the practice could nevertheless come to have non-negligible impact because (1) even a relatively small increase in the number of exceptionally talented people might have a significant effect; and (2) it is possible that some state would embark on a larger-scale eugenics program, perhaps by paying surrogate mothers. Other kinds of genetic engineering—such as the design of novel synthetic genes or insertion into the genome of promoter regions and other elements to control gene expression—might also become important over time. Even more exotic possibilities may exist, such as vats full of complexly structured cultured cortical tissue, or “uplifted” transgenic animals (perhaps some large-brained mammal such as the whale or elephant, enriched with human genes). These latter ones are wholly speculative, but over a longer time frame they perhaps cannot be completely discounted.
So far we have discussed germline interventions, ones that would be done on gametes or embryos. Somatic gene enhancements, by bypassing the generation cycle, could in principle produce impacts more quickly. However, they are technologically much more challenging. They require that the modified genes be inserted into a large number of cells in the living body—including, in the case of cognitive enhancement, the brain. Selecting among existing egg cells or embryos, in contrast, requires no gene insertion. Even such germline therapies as do involve modifying the genome (such as proofreading the genome or splicing in rare alleles) are far easier to implement at the gamete or the embryo stage, where one is dealing with a small number of cells. Furthermore, germline interventions on embryos can probably achieve greater effects than somatic interventions on adults, because the former would be able to shape early brain development whereas the latter would be limited to tweaking an existing structure. (Some of what could be done through somatic gene therapy might also be achievable by pharmacological means.)
Focusing therefore on germline interventions, we must take into account the generational lag delaying any large impact on the world.60 Even if the technology were perfected today and immediately put to use, it would take more than two decades for a genetically enhanced brood to reach maturity. Furthermore, with human applications there is normally a delay of at least one decade between proof of concept in the laboratory and clinical application, because of the need for extensive studies to determine safety. The simplest forms of genetic selection, however, could largely abrogate the need for such testing, since they would use standard fertility treatment techniques and genetic information to choose between embryos that might otherwise have been selected by chance.
Delays could also result from obstacles rooted not in a fear of failure (demand for safety testing) but in fear of success—demand for regulation driven by concerns about the moral permissibility of genetic selection or its wider social implications. Such concerns are likely to be more influential in some countries than in others, owing to differing cultural, historical, and religious contexts. Post-war Germany, for example, has chosen to give a wide berth to any reproductive practices that could be perceived to be even in the remotest way aimed at enhancement, a stance that is understandable given the particularly dark history of atrocities connected to the eugenics movement in that country. Other Western countries are likely to take a more liberal approach. And some countries—perhaps China or Singapore, both of which have long-term population policies—might not only permit but actively promote the use of genetic selection and genetic engineering to enhance the intelligence of their populations once the technology to do so is available.
Once the example has been set, and the results start to show, holdouts will have strong incentives to follow suit. Nations would face the prospect of becoming cognitive backwaters and losing out in economic, scientific, military, and prestige contests with competitors that embrace the new human enhancement technologies. Individuals within a society would see places at elite schools being filled with genetically selected children (who may also on average be prettier, healthier, and more conscientious) and will want their own offspring to have the same advantages. There is some chance that a large attitudinal shift could take place over a relatively short time, perhaps in as little as a decade, once the technology is proven to work and to provide a substantial benefit. Opinion surveys in the United States reveal a dramatic shift in public approval of in vitro fertilization after the birth of the first “test tube baby,” Louise Brown, in 1978. A few years earlier, only 18% of Americans said they would personally use IVF to treat infertility; yet in a poll taken shortly after the birth of Louise Brown, 53% said they would do so, and the number has continued to rise.61 (For comparison, in a poll taken in 2004, 28% of Americans approved of embryo selection for “strength or intelligence,” 58% approved of it for avoiding adult-onset cancer, and 68% approved of it to avoid fatal childhood disease.62)
If we add up the various delays—say five to ten years to gather the information needed for significantly effective selection among a set of IVF embryos (possibly much longer before stem cell-derived gametes are available for use in human reproduction), ten years to build significant uptake, and twenty to twenty-five years for the enhanced generation to reach an age where they start becoming productive, we find that germline enhancements are unlikely to have a significant impact on society before the middle of this century. From that point onward, however, the intelligence of significant segments of the adult population may begin to be boosted by genetic enhancements. The speed of the ascent would then greatly accelerate as cohorts conceived using more powerful next-generation genetic technologies (in particular stem cell-derived gametes and iterative embryo selection) enter the labor force.
With the full development of the genetic technologies described above (setting aside the more exotic possibilities such as intelligence in cultured neural tissue), it might be possible to ensure that new individuals are on average smarter than any human who has yet existed, with peaks that rise higher still. The potential of biological enhancement is thus ultimately high, probably sufficient for the attainment of at least weak forms of superintelligence. This should not be surprising. After all, dumb evolutionary processes have dramatically amplified the intelligence in the human lineage even compared with our close relatives the great apes and our own humanoid ancestors; and there is no reason to suppose Homo sapiens to have reached the apex of cognitive effectiveness attainable in a biological system. Far from being the smartest possible biological species, we are probably better thought of as the stupidest possible biological species capable of starting a technological civilization—a niche we filled because we got there first, not because we are in any sense optimally adapted to it.
Progress along the biological path is clearly feasible. The generational lag in germline interventions means that progress could not be nearly as sudden and abrupt as in scenarios involving machine intelligence. (Somatic gene therapies and pharmacological interventions could theoretically skip the generational lag, but they seem harder to perfect and are less likely to produce dramatic effects.) The ultimate potential of machine intelligence is, of course, vastly greater than that of organic intelligence. (One can get some sense of the magnitude of the gap by considering the speed differential between electronic components and nerve cells: even today’s transistors operate on a timescale ten million times shorter than that of biological neurons.) However, even comparatively moderate enhancements of biological cognition could have important consequences. In particular, cognitive enhancement could accelerate science and technology, including progress toward more potent forms of biological intelligence amplification and machine intelligence. Consider how the rate of progress in the field of artificial intelligence would change in a world where Average Joe is an intellectual peer of Alan Turing or John von Neumann, and where millions of people tower far above any intellectual giant of the past.63
A discussion of the strategic implications of cognitive enhancement will have to await a later chapter. But we can summarize this section by noting three conclusions: (1) at least weak forms of superintelligence are achievable by means of biotechnological enhancements; (2) the feasibility of cognitively enhanced humans adds to the plausibility that advanced forms of machine intelligence are feasible—because even if we were fundamentally unable to create machine intelligence (which there is no reason to suppose), machine intelligence might still be within reach of cognitively enhanced humans; and (3) when we consider scenarios stretching significantly into the second half of this century and beyond, we must take into account the probable emergence of a generation of genetically enhanced populations—voters, inventors, scientists—with the magnitude of enhancement escalating rapidly over subsequent decades.
Brain-computer interfaces
It is sometimes proposed that direct brain-computer interfaces, particularly implants, could enable humans to exploit the fortes of digital computing—perfect recall, speedy and accurate arithmetic calculation, and high-bandwidth data transmission—enabling the resulting hybrid system to radically outperform the unaugmented brain.64 But although the possibility of direct connections between human brains and computers has been demonstrated, it seems unlikely that such interfaces will be widely used as enhancements any time soon.65
To begin with, there are significant risks of medical complications—including infections, electrode displacement, hemorrhage, and cognitive decline—when implanting electrodes in the brain. Perhaps the most vivid illustration to date of the benefits that can be obtained through brain stimulation is the treatment of patients with Parkinson’s disease. The Parkinson’s implant is relatively simple: it does not really communicate with the brain but simply supplies a stimulating electric current to the subthalamic nucleus. A demonstration video shows a subject slumped in a chair, completely immobilized by the disease, then suddenly springing to life when the current is switched on: the subject now moves his arms, stands up and walks across the room, turns around and performs a pirouette. Yet even behind this especially simple and almost miraculously successful procedure, there lurk negatives. One study of Parkinson patients who had received deep brain implants showed reductions in verbal fluency, selective attention, color naming, and verbal memory compared with controls. Treated subjects also reported more cognitive complaints.66 Such risks and side effects might be tolerable if the procedure is used to alleviate severe disability. But in order for healthy subjects to volunteer themselves for neurosurgery, there would have to be some very substantial enhancement of normal functionality to be gained.
This brings us to the second reason to doubt that superintelligence will be achieved through cyborgization, namely that enhancement is likely to be far more difficult than therapy. Patients who suffer from paralysis might benefit from an implant that replaces their severed nerves or activates spinal motion pattern generators.67 Patients who are deaf or blind might benefit from artificial cochleae and retinas.68 Patients with Parkinson’s disease or chronic pain might benefit from deep brain stimulation that excites or inhibits activity in a particular area of the brain.69 What seems far more difficult to achieve is a high-bandwidth direct interaction between brain and computer to provide substantial increases in intelligence of a form that could not be more readily attained by other means. Most of the potential benefits that brain implants could provide in healthy subjects could be obtained at far less risk, expense, and inconvenience by using our regular motor and sensory organs to interact with computers located outside of our bodies. We do not need to plug a fiber optic cable into our brains in order to access the Internet. Not only can the human retina transmit data at an impressive rate of nearly 10 million bits per second, but it comes pre-packaged with a massive amount of dedicated wetware, the visual cortex, that is highly adapted to extracting meaning from this information torrent and to interfacing with other brain areas for further processing.70 Even if there were an easy way of pumping more information into our brains, the extra data inflow would do little to increase the rate at which we think and learn unless all the neural machinery necessary for making sense of the data were similarly upgraded. Since this includes almost all of the brain, what would really be needed is a “whole brain prosthesis-—which is just another way of saying artificial general intelligence. Yet if one had a human-level AI, one could dispense with neurosurgery: a computer might as well have a metal casing as one of bone. So this limiting case just takes us back to the AI path, which we have already examined.
Brain-computer interfacing has also been proposed as a way to get information out of the brain, for purposes of communicating with other brains or with machines.71 Such uplinks have helped patients with locked-in syndrome to communicate with the outside world by enabling them to move a cursor on a screen by thought.72 The bandwidth attained in such experiments is low: the patient painstakingly types out one slow letter after another at a rate of a few words per minute. One can readily imagine improved versions of this technology—perhaps a next-generation implant could plug into Broca’s area (a region in the frontal lobe involved in language production) and pick up internal speech.73 But whilst such a technology might assist some people with disabilities induced by stroke or muscular degeneration, it would hold little appeal for healthy subjects. The functionality it would provide is essentially that of a microphone coupled with speech recognition software, which is already commercially available—minus the pain, inconvenience, expense, and risks associated with neurosurgery (and minus at least some of the hyper-Orwellian overtones of an intracranial listening device). Keeping our machines outside of our bodies also makes upgrading easier.
But what about the dream of bypassing words altogether and establishing a connection between two brains that enables concepts, thoughts, or entire areas of expertise to be “downloaded” from one mind to another? We can download large files to our computers, including libraries with millions of books and articles, and this can be done over the course of seconds: could something similar be done with our brains? The apparent plausibility of this idea probably derives from an incorrect view of how information is stored and represented in the brain. As noted, the rate-limiting step in human intelligence is not how fast raw data can be fed into the brain but rather how quickly the brain can extract meaning and make sense of the data. Perhaps it will be suggested that we transmit meanings directly, rather than package them into sensory data that must be decoded by the recipient. There are two problems with this. The first is that brains, by contrast to the kinds of program we typically run on our computers, do not use standardized data storage and representation formats. Rather, each brain develops its own idiosyncratic representations of higher-level content. Which particular neuronal assemblies are recruited to represent a particular concept depends on the unique experiences of the brain in question (along with various genetic factors and stochastic physiological processes). Just as in artificial neural nets, meaning in biological neural networks is likely represented holistically in the structure and activity patterns of sizeable overlapping regions, not in discrete memory cells laid out in neat arrays.74 It would therefore not be possible to establish a simple mapping between the neurons in one brain and those in another in such a way that thoughts could automatically slide over from one to the other. In order for the thoughts of one brain to be intelligible to another, the thoughts need to be decomposed and packaged into symbols according to some shared convention that allows the symbols to be correctly interpreted by the receiving brain. This is the job of language.
In principle, one could imagine offloading the cognitive work of articulation and interpretation to an interface that would somehow read out the neural states in the sender’s brain and somehow feed in a bespoke pattern of activation to the receiver’s brain. But this brings us to the second problem with the cyborg scenario. Even setting aside the (quite immense) technical challenge of how to reliably read and write simultaneously from perhaps billions of individually addressable neurons, creating the requisite interface is probably an AI-complete problem. The interface would need to include a component able (in real-time) to map firing patterns in one brain onto semantically equivalent firing patterns in the other brain. The detailed multilevel understanding of the neural computation needed to accomplish such a task would seem to directly enable neuromorphic AI.
Despite these reservations, the cyborg route toward cognitive enhancement is not entirely without promise. Impressive work on the rat hippocampus has demonstrated the feasibility of a neural prosthesis that can enhance performance in a simple working-memory task.75 In its present version, the implant collects input from a dozen or two electrodes located in one area (“CA3”) of the hippocampus and projects onto a similar number of neurons in another area (“CA1”). A microprocessor is trained to discriminate between two different firing patterns in the first area (corresponding to two different memories, “right lever” or “left lever”) and to learn how these patterns are projected into the second area. This prosthesis can not only restore function when the normal neural connection between the two neural areas is blockaded, but by sending an especially clear token of a particular memory pattern to the second area it can enhance the performance on the memory task beyond what the rat is normally capable of. While a technical tour de force by contemporary standards, the study leaves many challenging questions unanswered: How well does the approach scale to greater numbers of memories? How well can we control the combinatorial explosion that otherwise threatens to make learning the correct mapping infeasible as the number of input and output neurons is increased? Does the enhanced performance on the test task come at some hidden cost, such as reduced ability to generalize from the particular stimulus used in the experiment, or reduced ability to unlearn the association when the environment changes? Would the test subjects still somehow benefit even if—unlike rats—they could avail themselves of external memory aids such as pen and paper? And how much harder would it be to apply a similar method to other parts of the brain? Whereas the present prosthesis takes advantage of the relatively simple feed-forward structure of parts of the hippocampus (basically serving as a unidirectional bridge between areas CA3 and CA1), other structures in the cortex involve convoluted feedback loops which greatly increase the complexity of the wiring diagram and, presumably, the difficulty of deciphering the functionality of any embedded group of neurons.
One hope for the cyborg route is that the brain, if permanently implanted with a device connecting it to some external resource, would over time learn an effective mapping between its own internal cognitive states and the inputs it receives from, or the outputs accepted by, the device. Then the implant itself would not need to be intelligent; rather, the brain would intelligently adapt to the interface, much as the brain of an infant gradually learns to interpret the signals arriving from receptors in its eyes and ears.76 But here again one must question how much would really be gained. Suppose that the brain’s plasticity were such that it could learn to detect patterns in some new input stream arbitrary projected onto some part of the cortex by means of a brain-computer interface: why not project the same information onto the retina instead, as a visual pattern, or onto the cochlea as sounds? The low-tech alternative avoids a thousand complications, and in either case the brain could deploy its pattern-recognition mechanisms and plasticity to learn to make sense of the information.
Networks and organizations
Another conceivable path to superintelligence is through the gradual enhancement of networks and organizations that link individual human minds with one another and with various artifacts and bots. The idea here is not that this would enhance the intellectual capacity of individuals enough to make them superintelligent, but rather that some system composed of individuals thus networked and organized might attain a form of superintelligence—what in the next chapter we will elaborate as “collective superintelligence.”77
Humanity has gained enormously in collective intelligence over the course of history and prehistory. The gains come from many sources, including innovations in communications technology, such as writing and printing, and above all the introduction of language itself; increases in the size of the world population and the density of habitation; various improvements in organizational techniques and epistemic norms; and a gradual accumulation of institutional capital. In general terms, a system’s collective intelligence is limited by the abilities of its member minds, the overheads in communicating relevant information between them, and the various distortions and inefficiencies that pervade human organizations. If communication overheads are reduced (including not only equipment costs but also response latencies, time and attention burdens, and other factors), then larger and more densely connected organizations become feasible. The same could happen if fixes are found for some of the bureaucratic deformations that warp organizational life—wasteful status games, mission creep, concealment or falsification of information, and other agency problems. Even partial solutions to these problems could pay hefty dividends for collective intelligence.
The technological and institutional innovations that could contribute to the growth of our collective intelligence are many and various. For example, subsidized prediction markets might foster truth-seeking norms and improve forecasting on contentious scientific and social issues.78 Lie detectors (should it prove feasible to make ones that are reliable and easy to use) could reduce the scope for deception in human affairs.79 Self-deception detectors might be even more powerful.80 Even without newfangled brain technologies, some forms of deception might become harder to practice thanks to increased availability of many kinds of data, including reputations and track records, or the promulgation of strong epistemic norms and rationality culture. Voluntary and involuntary surveillance will amass vast amounts of information about human behavior. Social networking sites are already used by over a billion people to share personal details: soon, these people might begin uploading continuous life recordings from microphones and video cameras embedded in their smart phones or eyeglass frames. Automated analysis of such data streams will enable many new applications (sinister as well as benign, of course).81
Growth in collective intelligence may also come from more general organizational and economic improvements, and from enlarging the fraction of the world’s population that is educated, digitally connected, and integrated into global intellectual culture.82
The Internet stands out as a particularly dynamic frontier for innovation and experimentation. Most of its potential may still remain unexploited. Continuing development of an intelligent Web, with better support for deliberation, de-biasing, and judgment aggregation, might make large contributions to increasing the collective intelligence of humanity as a whole or of particular groups.
But what of the seemingly more fanciful idea that the Internet might one day “wake up”? Could the Internet become something more than just the backbone of a loosely integrated collective superintelligence—something more like a virtual skull housing an emerging unified super-intellect? (This was one of the ways that superintelligence could arise according to Vernor Vinge’s influential 1993 essay, which coined the term “technological singularity.”83) Against this one could object that machine intelligence is hard enough to achieve through arduous engineering, and that it is incredible to suppose that it will arise spontaneously. However, the story need not be that some future version of the Internet suddenly becomes superintelligent by mere happenstance. A more plausible version of the scenario would be that the Internet accumulates improvements through the work of many people over many years—work to engineer better search and information filtering algorithms, more powerful data representation formats, more capable autonomous software agents, and more efficient protocols governing the interactions between such bots—and that myriad incremental improvements eventually create the basis for some more unified form of web intelligence. It seems at least conceivable that such a web-based cognitive system, supersaturated with computer power and all other resources needed for explosive growth save for one crucial ingredient, could, when the final missing constituent is dropped into the cauldron, blaze up with superintelligence. This type of scenario, though, converges into another possible path to superintelligence, that of artificial general intelligence, which we have already discussed.
Summary
The fact that there are many paths that lead to superintelligence should increase our confidence that we will eventually get there. If one path turns out to be blocked, we can still progress.
That there are multiple paths does not entail that there are multiple destinations. Even if significant intelligence amplification were first achieved along one of the non-machine-intelligence paths, this would not render machine intelligence irrelevant. Quite the contrary: enhanced biological or organizational intelligence would accelerate scientific and technological developments, potentially hastening the arrival of more radical forms of intelligence amplification such as whole brain emulation and AI.
This is not to say that it is a matter of indifference how we get to machine superintelligence. The path taken to get there could make a big difference to the eventual outcome. Even if the ultimate capabilities that are obtained do not depend much on the trajectory, how those capabilities will be used—how much control we humans have over their disposition—might well depend on details of our approach. For example, enhancements of biological or organizational intelligence might increase our ability to anticipate risk and to design machine superintelligence that is safe and beneficial. (A full strategic assessment involves many complexities, and will have to await Chapter 14.)
True superintelligence (as opposed to marginal increases in current levels of intelligence) might plausibly first be attained via the AI path. There are, however, many fundamental uncertainties along this path. This makes it difficult to rigorously assess how long the path is or how many obstacles there are along the way. The whole brain emulation path also has some chance of being the quickest route to superintelligence. Since progress along this path requires mainly incremental technological advances rather than theoretical breakthroughs, a strong case can be made that it will eventually succeed. It seems fairly likely, however, that even if progress along the whole brain emulation path is swift, artificial intelligence will nevertheless be first to cross the finishing line: this is because of the possibility of neuromorphic AIs based on partial emulations.
Biological cognitive enhancements are clearly feasible, particularly ones based on genetic selection. Iterated embryo selection currently seems like an especially promising technology. Compared with possible breakthroughs in machine intelligence, however, biological enhancements would be relatively slow and gradual. They would, at best, result in relatively weak forms of superintelligence (more on this shortly).
The clear feasibility of biological enhancement should increase our confidence that machine intelligence is ultimately achievable, since enhanced human scientists and engineers will be able to make more and faster progress than their au naturel counterparts. Especially in scenarios in which machine intelligence is delayed beyond mid-century, the increasingly cognitively enhanced cohorts coming onstage will play a growing role in subsequent developments.
Brain-computer interfaces look unlikely as a source of superintelligence. Improvements in networks and organizations might result in weakly superintelligent forms of collective intelligence in the long run; but more likely, they will play an enabling role similar to that of biological cognitive enhancement, gradually increasing humanity’s effective ability to solve intellectual problems. Compared with biological enhancements, advances in networks and organization will make a difference sooner—in fact, such advances are occurring continuously and are having a significant impact already. However, improvements in networks and organizations may yield narrower increases in our problem-solving capacity than will improvements in biological cognition—boosting “collective intelligence” rather than “quality intelligence,” to anticipate a distinction we are about to introduce in the next chapter.